Análisis Factorial Exploratorio II
0. Objetivo del práctico
El objetivo de este práctico revisar como realizar un Análisis factorial Exploratorio en R considerando la selección del número de factores, la extracción de factores, la rotación, la selección del modelo final y su interpretación, y el cálculo de puntuaciones factoriales. Este en una continuación del práctico anterior, donde realziamos la gestión de datos y la comprobación de los supuestos del análisis.
1. Carga y gestión de datos y librerias
Cargamos nuevamente la base de datos de PNUD 2015, que incluye los siguientes ítem. Con estos esperamos revisar si existen estructuras latentes en como las personas evalúan las oportunidades que entrega Chile. Además eliminamos los casos perdidos y atípicos. Para los detalles estas decisiones, revisar el práctico anterior.
Cargamos el paquete “psych” que nos permitirá realizar en análisis factorial exporatorio (AFE), “GPArotation” para poder hacer rotación promax, y “dplyr()” para gestión de datos.
library(psych)
library(GPArotation)
library(dplyr)
datosog <- read.csv("https://raw.githubusercontent.com/Clases-GabrielSotomayor/pruebapagina/master/static/slides/data/EDH_2013_csv.csv")
datoslw <- datosog %>%
select(cor, salud = P25a,ingr = P25b, trab = P25c, educ = P25d, vivi = P25e, segur = P25f, medio = P25g, liber = P25h, proye = P25i) %>%
mutate(across(everything(), ~na_if(.x, 9))) %>%
mutate(across(everything(), ~na_if(.x, 8))) %>%
na.omit()
# Tratamiento de casos atípicos
mean <- colMeans(datoslw[, 2:10], na.rm = TRUE)
Sx <- cov(datoslw[, 2:10], use = "complete.obs") # matriz de varianza-covarianza
D2 <- mahalanobis(datoslw[, 2:10], center = mean, cov = Sx)
datoslw$sigmahala <- (1 - pchisq(D2, df = 9)) # Usando 9 grados de libertad
# Filtrar casos atípicos
datoslw <- datoslw %>%
filter(sigmahala > 0.001) %>%
select(-sigmahala)
# Guardar ID para hacer el merge luego con otras variables
id <- datoslw$cor
datoslw$cor <- NULL
2. Análisis factorial exploratorio
Gráfico de sedimentación
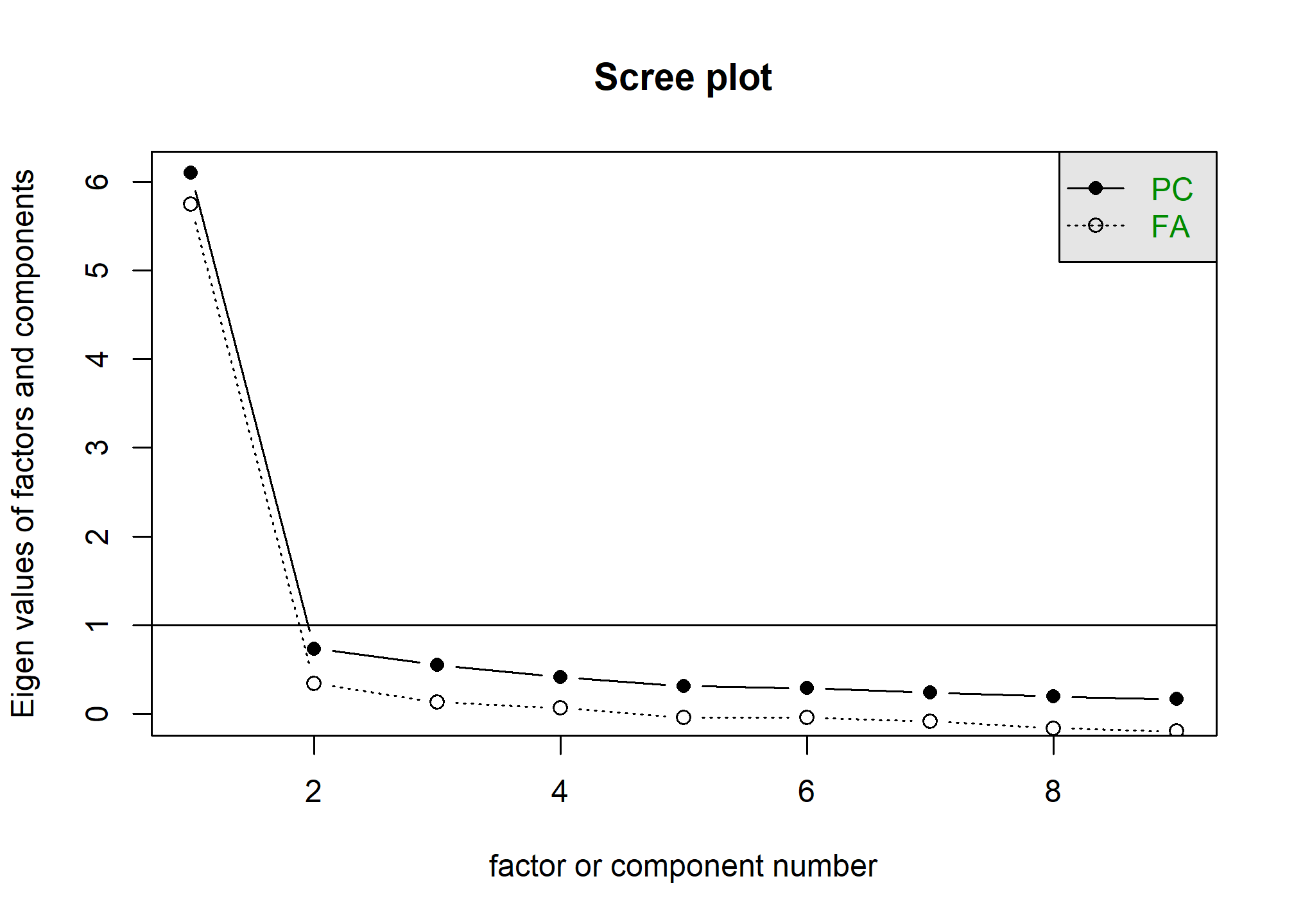
El gráfico de sedimentación (scree plot) nos ayuda a decidir cuántos factores mantener en el análisis. Para ello, utilizaremos la función scree() de la librería psych.
El gráfico de sedimentación muestra la proporción de varianza explicada por cada factor en el eje Y y el número de factores en el eje X. Se busca identificar un punto de inflexión en la gráfica, donde la pendiente de la curva se aplana. Este punto indica la cantidad de factores que se deben retener.
scree(datoslw)
Selección del número de factores
Para decidir cuántos factores incluir en el análisis factorial, utilizaremos la función fa.parallel() de la librería psych. Esta función utiliza análisis paralelos para determinar cuántos factores se deben retener.
set.seed(231) #fijamos semilla para tener resutlados replicables
nofactor <- fa.parallel(datoslw, fa="fa")
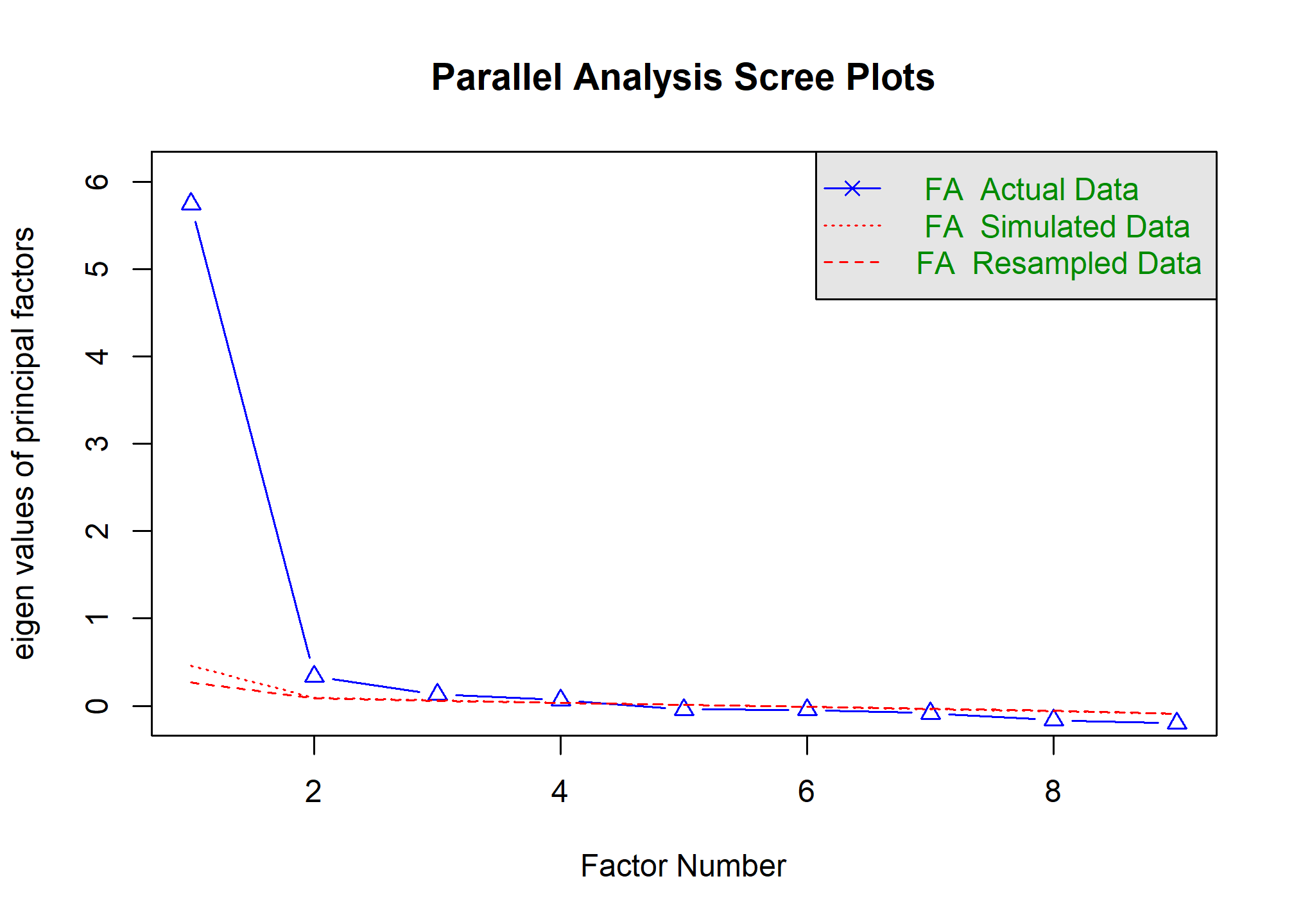
## Parallel analysis suggests that the number of factors = 4 and the number of components = NA
nofactor$fa.values
## [1] 5.74704845 0.33961296 0.13040790 0.06429939 -0.04202411 -0.04635429
## [7] -0.08522970 -0.16409153 -0.19662041
En este caso, el análisis paralelo sugiere retener 4 factores.
Análisis factorial exploratorio con diferentes configuraciones
Ahora realizaremos el análisis factorial exploratorio utilizando diferentes configuraciones, como el número de factores, rotaciones y correlaciones. Esto nos permitirá comparar y seleccionar el mejor modelo.
Cuando se trabaja con variables ordinales o categóricas en un análisis factorial exploratorio, es más apropiado utilizar correlaciones policóricas, ya que tienen en cuenta la naturaleza no lineal y discreta de los datos. Dado que nuestras variables tienen 7 categorías probamos ambos tipos de correlaciones para ver el nivel de ajuste. El análisis con correlaciones policóricas explica una mayor proporción de la varianza por lo que se seguirá con estas.
# Prueba de Modelos segun parallel
fa(datoslw,nfactors=4, fm="minres",rotate="none")
## Factor Analysis using method = minres
## Call: fa(r = datoslw, nfactors = 4, rotate = "none", fm = "minres")
## Standardized loadings (pattern matrix) based upon correlation matrix
## MR1 MR2 MR3 MR4 h2 u2 com
## salud 0.76 0.13 -0.08 -0.02 0.60 0.4030 1.1
## ingr 0.83 0.46 -0.25 0.20 1.00 0.0048 1.9
## trab 0.83 -0.01 -0.11 -0.19 0.74 0.2580 1.1
## educ 0.87 0.08 0.05 -0.23 0.82 0.1806 1.2
## vivi 0.86 0.04 0.11 -0.17 0.78 0.2229 1.1
## segur 0.69 0.21 0.34 0.14 0.66 0.3442 1.8
## medio 0.78 -0.11 0.15 0.14 0.67 0.3328 1.2
## liber 0.83 -0.47 -0.07 0.19 0.95 0.0463 1.7
## proye 0.81 -0.29 -0.09 -0.02 0.75 0.2530 1.3
##
## MR1 MR2 MR3 MR4
## SS loadings 5.88 0.59 0.25 0.23
## Proportion Var 0.65 0.07 0.03 0.03
## Cumulative Var 0.65 0.72 0.75 0.77
## Proportion Explained 0.85 0.09 0.04 0.03
## Cumulative Proportion 0.85 0.93 0.97 1.00
##
## Mean item complexity = 1.4
## Test of the hypothesis that 4 factors are sufficient.
##
## df null model = 36 with the objective function = 7.24 with Chi Square = 11488.26
## df of the model are 6 and the objective function was 0.02
##
## The root mean square of the residuals (RMSR) is 0.01
## The df corrected root mean square of the residuals is 0.02
##
## The harmonic n.obs is 1591 with the empirical chi square 4.85 with prob < 0.56
## The total n.obs was 1591 with Likelihood Chi Square = 34.2 with prob < 6.2e-06
##
## Tucker Lewis Index of factoring reliability = 0.985
## RMSEA index = 0.054 and the 90 % confidence intervals are 0.038 0.073
## BIC = -10.03
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## MR1 MR2 MR3 MR4
## Correlation of (regression) scores with factors 0.99 0.97 0.75 0.79
## Multiple R square of scores with factors 0.97 0.93 0.56 0.63
## Minimum correlation of possible factor scores 0.95 0.86 0.13 0.26
# Prueba con 4 factores y correlación polychoric
fa(datoslw, nfactors=4, rotate="none", cor = "poly")
## Factor Analysis using method = minres
## Call: fa(r = datoslw, nfactors = 4, rotate = "none", cor = "poly")
## Standardized loadings (pattern matrix) based upon correlation matrix
## MR1 MR2 MR3 MR4 h2 u2 com
## salud 0.78 0.13 -0.17 0.15 0.67 0.3281 1.2
## ingr 0.82 0.30 -0.14 0.22 0.84 0.1611 1.5
## trab 0.85 -0.02 -0.19 -0.08 0.76 0.2350 1.1
## educ 0.89 0.09 -0.12 -0.18 0.84 0.1559 1.1
## vivi 0.88 0.07 -0.04 -0.19 0.81 0.1906 1.1
## segur 0.74 0.35 0.42 -0.03 0.85 0.1471 2.1
## medio 0.80 -0.08 0.17 0.05 0.68 0.3158 1.1
## liber 0.85 -0.48 0.13 0.12 0.99 0.0094 1.7
## proye 0.83 -0.30 -0.02 -0.03 0.78 0.2216 1.3
##
## MR1 MR2 MR3 MR4
## SS loadings 6.18 0.57 0.32 0.16
## Proportion Var 0.69 0.06 0.04 0.02
## Cumulative Var 0.69 0.75 0.79 0.80
## Proportion Explained 0.85 0.08 0.04 0.02
## Cumulative Proportion 0.85 0.93 0.98 1.00
##
## Mean item complexity = 1.4
## Test of the hypothesis that 4 factors are sufficient.
##
## df null model = 36 with the objective function = 8.2 with Chi Square = 13004.7
## df of the model are 6 and the objective function was 0.03
##
## The root mean square of the residuals (RMSR) is 0.01
## The df corrected root mean square of the residuals is 0.02
##
## The harmonic n.obs is 1591 with the empirical chi square 4.33 with prob < 0.63
## The total n.obs was 1591 with Likelihood Chi Square = 42.42 with prob < 1.5e-07
##
## Tucker Lewis Index of factoring reliability = 0.983
## RMSEA index = 0.062 and the 90 % confidence intervals are 0.045 0.08
## BIC = -1.82
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## MR1 MR2 MR3 MR4
## Correlation of (regression) scores with factors 0.99 0.95 0.82 0.72
## Multiple R square of scores with factors 0.98 0.90 0.67 0.51
## Minimum correlation of possible factor scores 0.95 0.79 0.35 0.02
La rotación de factores es un paso importante en el AFE, ya que facilita la interpretación de los resultados. La rotación puede ser ortogonal o oblicua. La rotación ortogonal (e.g. varimax) asume que los factores no están correlacionados, mientras que la rotación oblicua (e.g. promax) permite que los factores estén correlacionados.
Para decidir qué rotación utilizar, es útil explorar la correlación entre los factores. Si las correlaciones son bajas (menores a 0.3), la rotación ortogonal es apropiada. Si las correlaciones son altas, se recomienda utilizar la rotación oblicua.
# Prueba con 4 factores y rotación varimax y promax
fa(datoslw, nfactors=4, rotate="varimax", cor = "poly")
## Factor Analysis using method = minres
## Call: fa(r = datoslw, nfactors = 4, rotate = "varimax", cor = "poly")
## Standardized loadings (pattern matrix) based upon correlation matrix
## MR2 MR4 MR3 MR1 h2 u2 com
## salud 0.35 0.63 0.25 0.31 0.67 0.3281 2.5
## ingr 0.26 0.75 0.37 0.26 0.84 0.1611 2.0
## trab 0.47 0.49 0.21 0.51 0.76 0.2350 3.3
## educ 0.40 0.46 0.34 0.60 0.84 0.1559 3.4
## vivi 0.42 0.40 0.39 0.57 0.81 0.1906 3.6
## segur 0.24 0.31 0.81 0.22 0.85 0.1471 1.7
## medio 0.57 0.34 0.42 0.25 0.68 0.3158 3.0
## liber 0.91 0.25 0.22 0.21 0.99 0.0094 1.4
## proye 0.71 0.30 0.19 0.39 0.78 0.2216 2.2
##
## MR2 MR4 MR3 MR1
## SS loadings 2.46 1.94 1.42 1.41
## Proportion Var 0.27 0.22 0.16 0.16
## Cumulative Var 0.27 0.49 0.65 0.80
## Proportion Explained 0.34 0.27 0.20 0.19
## Cumulative Proportion 0.34 0.61 0.81 1.00
##
## Mean item complexity = 2.6
## Test of the hypothesis that 4 factors are sufficient.
##
## df null model = 36 with the objective function = 8.2 with Chi Square = 13004.7
## df of the model are 6 and the objective function was 0.03
##
## The root mean square of the residuals (RMSR) is 0.01
## The df corrected root mean square of the residuals is 0.02
##
## The harmonic n.obs is 1591 with the empirical chi square 4.33 with prob < 0.63
## The total n.obs was 1591 with Likelihood Chi Square = 42.42 with prob < 1.5e-07
##
## Tucker Lewis Index of factoring reliability = 0.983
## RMSEA index = 0.062 and the 90 % confidence intervals are 0.045 0.08
## BIC = -1.82
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## MR2 MR4 MR3 MR1
## Correlation of (regression) scores with factors 0.99 0.83 0.87 0.80
## Multiple R square of scores with factors 0.97 0.70 0.75 0.64
## Minimum correlation of possible factor scores 0.94 0.39 0.50 0.29
fa(datoslw, nfactors=4, rotate="promax", cor = "poly")
## Factor Analysis using method = minres
## Call: fa(r = datoslw, nfactors = 4, rotate = "promax", cor = "poly")
## Standardized loadings (pattern matrix) based upon correlation matrix
## MR2 MR1 MR4 MR3 h2 u2 com
## salud 0.09 0.13 0.67 -0.04 0.67 0.3281 1.1
## ingr -0.06 -0.01 0.89 0.10 0.84 0.1611 1.0
## trab 0.17 0.58 0.26 -0.11 0.76 0.2350 1.7
## educ -0.01 0.76 0.13 0.07 0.84 0.1559 1.1
## vivi 0.05 0.71 0.02 0.17 0.81 0.1906 1.1
## segur -0.03 0.05 0.03 0.89 0.85 0.1471 1.0
## medio 0.51 0.04 0.10 0.28 0.68 0.3158 1.7
## liber 1.11 -0.11 -0.02 -0.02 0.99 0.0094 1.0
## proye 0.67 0.32 0.00 -0.08 0.78 0.2216 1.5
##
## MR2 MR1 MR4 MR3
## SS loadings 2.23 2.14 1.76 1.10
## Proportion Var 0.25 0.24 0.20 0.12
## Cumulative Var 0.25 0.49 0.68 0.80
## Proportion Explained 0.31 0.30 0.24 0.15
## Cumulative Proportion 0.31 0.60 0.85 1.00
##
## With factor correlations of
## MR2 MR1 MR4 MR3
## MR2 1.00 0.79 0.69 0.61
## MR1 0.79 1.00 0.83 0.68
## MR4 0.69 0.83 1.00 0.70
## MR3 0.61 0.68 0.70 1.00
##
## Mean item complexity = 1.2
## Test of the hypothesis that 4 factors are sufficient.
##
## df null model = 36 with the objective function = 8.2 with Chi Square = 13004.7
## df of the model are 6 and the objective function was 0.03
##
## The root mean square of the residuals (RMSR) is 0.01
## The df corrected root mean square of the residuals is 0.02
##
## The harmonic n.obs is 1591 with the empirical chi square 4.33 with prob < 0.63
## The total n.obs was 1591 with Likelihood Chi Square = 42.42 with prob < 1.5e-07
##
## Tucker Lewis Index of factoring reliability = 0.983
## RMSEA index = 0.062 and the 90 % confidence intervals are 0.045 0.08
## BIC = -1.82
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## MR2 MR1 MR4 MR3
## Correlation of (regression) scores with factors 1.00 0.96 0.95 0.94
## Multiple R square of scores with factors 0.99 0.92 0.90 0.88
## Minimum correlation of possible factor scores 0.98 0.85 0.81 0.75
# Modelo final
modelofinal <- fa(datoslw, nfactors=4, rotate="promax", cor = "poly")
Después de comparar los resultados, decidimos utilizar un modelo con 4 factores y rotación promax.
Visualización de resultados
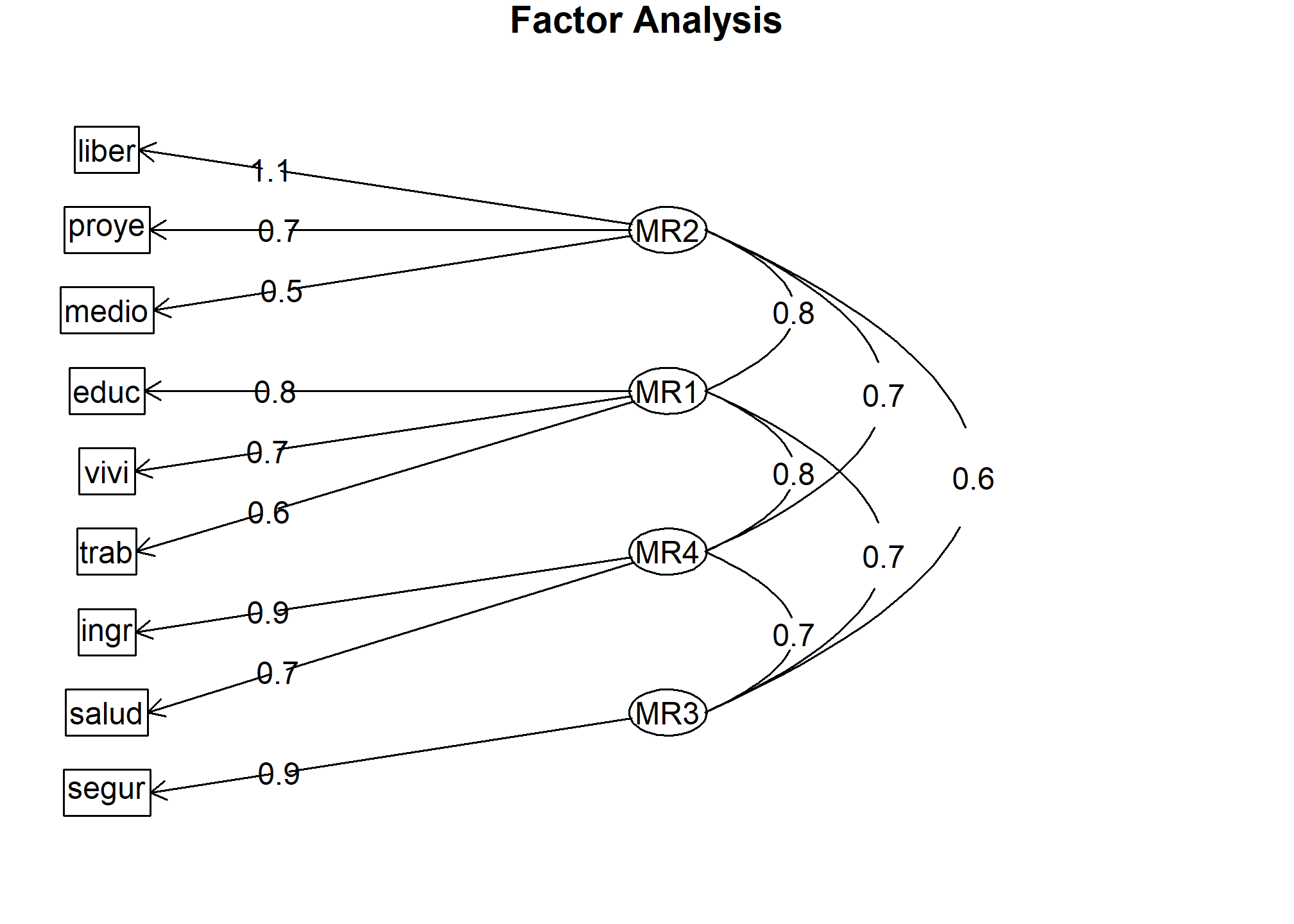
Podemos observar los resultados del análisis con el comando fa.diagram(), que nos muestra las cargas factoriales de los ítems del modelo con cada uno de los factores latentes.
fa.diagram(modelofinal)
Cálculo de puntuaciones factoriales
Finalmente, podemos calcular las puntuaciones factoriales para cada individuo en nuestra muestra utilizando la función factor.scores(). Estas puntuaciones pueden ser utilizadas en análisis posteriores o como variables en otros modelos
#Extracción de puntuaciones factoriales
#Extraemos las puntuaciones facotriales del objeto del modelo final
summary(modelofinal$scores)
## MR2 MR1 MR4 MR3
## Min. :-2.2316 Min. :-1.97324 Min. :-1.76865 Min. :-1.59191
## 1st Qu.:-0.6128 1st Qu.:-0.68464 1st Qu.:-0.72798 1st Qu.:-0.83273
## Median : 0.1549 Median : 0.04866 Median : 0.03374 Median :-0.03984
## Mean : 0.0000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000
## 3rd Qu.: 0.7362 3rd Qu.: 0.71420 3rd Qu.: 0.72924 3rd Qu.: 0.72964
## Max. : 1.8247 Max. : 2.02736 Max. : 2.13972 Max. : 2.21424
#Guardamos los puntajes en la base
basefinal<-cbind(datoslw,modelofinal$scores )
#Pegamos la variable GSE de la base de datos original
datosog<- datosog |> filter(datosog$cor%in% id)
basefinal<-cbind(basefinal,datosog$GSEo)
basefinal$gse<-factor(basefinal$`datosog$GSEo`,1:4,labels = c("ABC1" , "C2" , "C3" , "D"))
#Comparamos el
aggregate(basefinal$MR1,list(basefinal$gse),mean) #Derechos sociales
## Group.1 x
## 1 ABC1 0.6963777
## 2 C2 0.1051471
## 3 C3 -0.1031959
## 4 D -0.1437581
aggregate(basefinal$MR2,list(basefinal$gse),mean) #Derechos individuales
## Group.1 x
## 1 ABC1 0.6682424
## 2 C2 0.1791931
## 3 C3 -0.1092567
## 4 D -0.1634878
aggregate(basefinal$MR3,list(basefinal$gse),mean) #Jubilación
## Group.1 x
## 1 ABC1 0.737541178
## 2 C2 0.009917541
## 3 C3 -0.153449152
## 4 D -0.067562450
aggregate(basefinal$MR4,list(basefinal$gse),mean) #Seguridad
## Group.1 x
## 1 ABC1 0.68272476
## 2 C2 0.02102507
## 3 C3 -0.11103079
## 4 D -0.09876178