Análisis de conglomerados no jerárquicos
0. Objetivo del Práctico
El objetivo de este práctico es realizar un análisis de conglomerados no jerárquicos sobre una serie de opiniones ideológicas de los individuos encuestados en la sexta ola del estudio ELSOC. Utilizaremos el método de k-medias para identificar grupos que compartan perfiles ideológicos similares con base en una serie de preguntas sobre temas sociales y políticos. Al final del ejercicio, los estudiantes deberían comprender cómo esta técnica permite descubrir agrupamientos significativos dentro de los datos, permitiendo caracterizar diferentes perfiles ideológicos sin necesidad de una hipótesis a priori.
1. Carga y Preparación de los Datos
if (!requireNamespace("pacman", quietly = TRUE)) install.packages("pacman")
pacman::p_load(dplyr,factoextra , corrplot, knitr, kableExtra)
temp <- tempfile()
download.file("https://github.com/GabrielSotomayorl/aadi2024/raw/refs/heads/main/content/example/input/data/ELSOC_Long_2016_2022_v1.00.RData", temp)
load(temp)
unlink(temp)
elsoc<- elsoc_long_2016_2022.2 %>%
filter(ola == 6) %>%
mutate(across(c(c37_01:c37_09), ~ ifelse(. < 0, NA, .))) %>%
filter(!(is.na(c37_01)|is.na(c37_02)|is.na(c37_03)|is.na(c37_04)|is.na(c37_05)|is.na(c37_06)|is.na(c37_07)|is.na(c37_08)))
medias <- elsoc %>%
summarise(across(c(c37_01:c37_08), mean, na.rm = TRUE))
preg<- c(
"Las parejas homosexuales deberían poder adoptar hijos",
"El aborto debe ser legal bajo cualquier circunstancia",
"El Estado de Chile, más que los privados, debería ser el principal proveedor de educación",
"Cada persona debiera asegurarse por sí misma su futura pensión para la tercera edad",
"Chile debería tomar medidas más drásticas para impedir el ingreso de inmigrantes al país",
"La educación sexual de los niños debería ser responsabilidad exclusiva de los padres",
"Se deberían clausurar empresas contaminantes, incluso si esto implica un aumento en el desempleo",
"El gasto social debe destinarse únicamente a los más pobres y vulnerables")
# Crear la tabla con los resultados y las descripciones
resultados <- data.frame(
Descripción = preg,
Media = as.numeric(medias)
)
# Mostrar la tabla con kable
kable(resultados, caption = "Medias de Opiniones en Encuesta ELSOC", format = "html", align = "l", col.names = c("Descripción", "Media"))
| Descripción | Media |
|---|---|
| Las parejas homosexuales deberían poder adoptar hijos | 3.203502 |
| El aborto debe ser legal bajo cualquier circunstancia | 2.684179 |
| El Estado de Chile, más que los privados, debería ser el principal proveedor de educación | 4.074879 |
| Cada persona debiera asegurarse por sí misma su futura pensión para la tercera edad | 3.049517 |
| Chile debería tomar medidas más drásticas para impedir el ingreso de inmigrantes al país | 4.186594 |
| La educación sexual de los niños debería ser responsabilidad exclusiva de los padres | 3.184179 |
| Se deberían clausurar empresas contaminantes, incluso si esto implica un aumento en el desempleo | 3.681763 |
| El gasto social debe destinarse únicamente a los más pobres y vulnerables | 3.170290 |
Las variables corresponden a escalas de acuerdo (¿Cuán de acuerdo o en desacuerdo está usted con cada una de las siguientes afirmaciones?) donde 1 indica menor acuerdo y 5 mayor acuerdo.
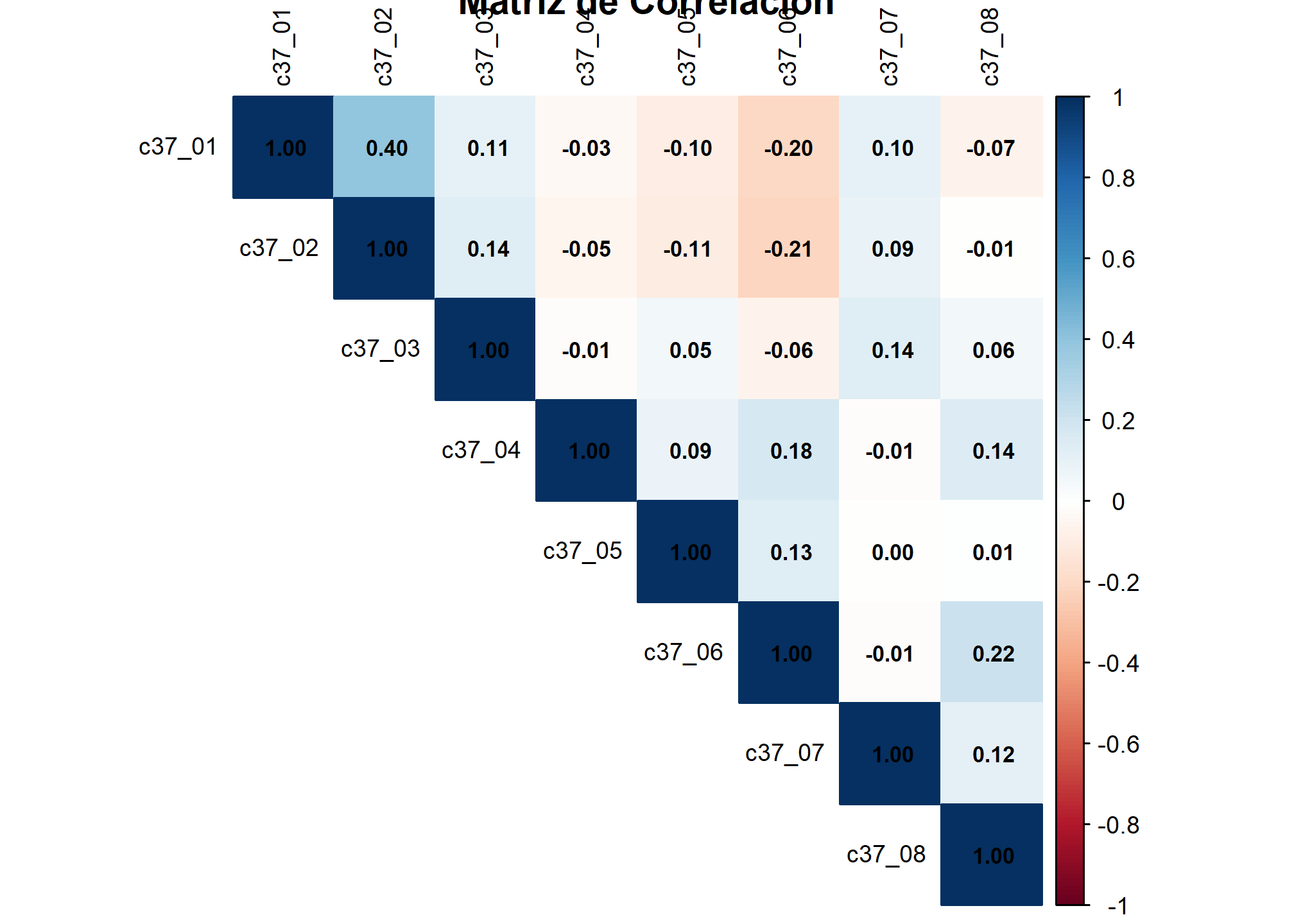
2. Análisis de Correlación entre Variables
Antes de proceder al análisis de conglomerados, es importante entender las relaciones entre nuestras variables mediante un análisis de correlación.
# Calcular la matriz de correlación
corr_matrix <- cor(elsoc %>% select(c37_01:c37_08), use = "complete.obs")
# Visualizar la matriz de correlación con números y colores
corrplot(corr_matrix, method = "color", type = "upper", tl.col = "black", tl.cex = 0.8, title = "Matriz de Correlación", addCoef.col = "black", number.cex = 0.7)
3. Estandarización de las Variables
Para asegurar que todas las variables contribuyan equitativamente al análisis, es fundamental estandarizarlas, cuando las variables tienen diferentes rangos. En este caso, dado que todas tienen la misma escala optaremos por no estandarizar.
# Estandarizar las variables
elsoc_vars <- elsoc %>%
select(c37_01:c37_08) #%>%
#scale()
# Verificar los datos estandarizados
head(elsoc_vars)
## c37_01 c37_02 c37_03 c37_04 c37_05 c37_06 c37_07 c37_08
## 1 4 2 5 2 5 2 4 4
## 2 3 2 5 4 5 4 3 4
## 3 1 4 5 4 5 2 4 4
## 4 3 1 4 2 5 2 4 2
## 5 1 5 5 4 5 1 4 4
## 6 3 4 3 4 4 2 4 3
4. Determinación del Número Óptimo de Conglomerados
Para determinar el número óptimo de conglomerados, utilizaremos el método del codo.
# Método del codo para determinar el número óptimo de conglomerados
fviz_nbclust(elsoc_vars, kmeans, method = "wss") +
labs(title = "Determinación del Número Óptimo de Conglomerados - Método del Codo")
## Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
## ℹ Please use the `linewidth` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
## Warning: The `size` argument of `element_rect()` is deprecated as of ggplot2 3.4.0.
## ℹ Please use the `linewidth` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
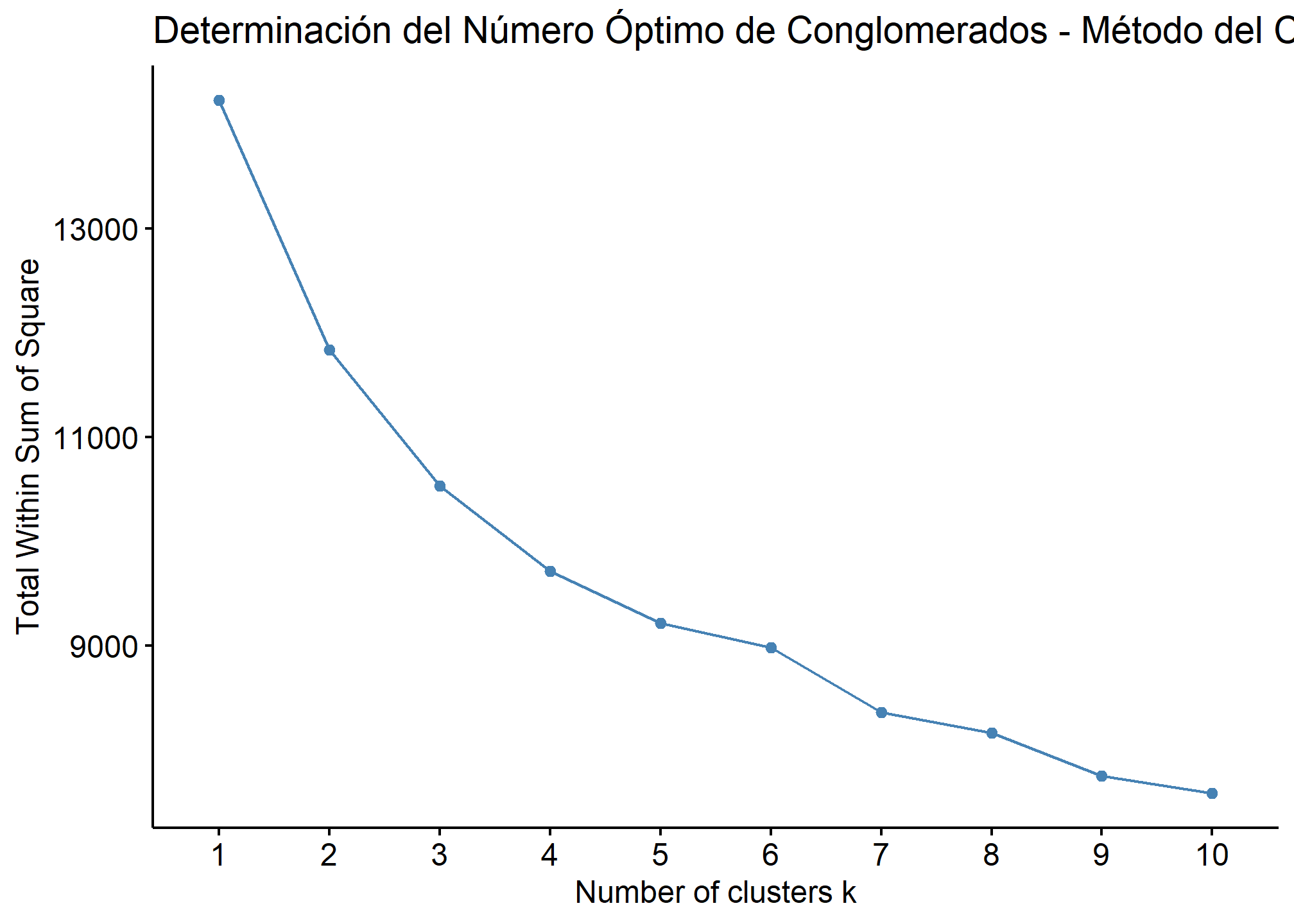
5. Análisis de Conglomerados k-medias
El siguiente paso consiste en realizar el análisis de conglomerados utilizando el método de k-medias para identificar los perfiles ideológicos. Considerando la información del método del codo haremos un análisis con 4 conglomerados.
set.seed(123) # Para reproducibilidad
# Aplicar k-medias con 4 conglomerados
kmeans_result <- kmeans(elsoc_vars, centers = 4, nstart = 25)
# Agregar los conglomerados al dataframe original
elsoc$conglomerado <- kmeans_result$cluster
# Ver la asignación de los primeros registros
head(elsoc %>% select(c37_01:c37_08, conglomerado))
## c37_01 c37_02 c37_03 c37_04 c37_05 c37_06 c37_07 c37_08 conglomerado
## 1 4 2 5 2 5 2 4 4 1
## 2 3 2 5 4 5 4 3 4 2
## 3 1 4 5 4 5 2 4 4 4
## 4 3 1 4 2 5 2 4 2 1
## 5 1 5 5 4 5 1 4 4 3
## 6 3 4 3 4 4 2 4 3 3
6. Caracterización de los Conglomerados
Ahora caracterizaremos los conglomerados obtenidos, calculando los promedios de cada variable por conglomerado para identificar los perfiles ideológicos.
caracterizacion <- elsoc %>%
group_by(conglomerado) %>%
summarise(
across(c(c37_01:c37_08), mean, na.rm = TRUE),
cantidad_individuos = n()
)
# Crear un tibble para presentar los resultados con nombres más claros
caracterizacion_tidy <- caracterizacion %>%
rename(
"Conglomerado" = conglomerado,
"Adopción Homoparental" = c37_01,
"Aborto" = c37_02,
"Rol del Estado en Educación" = c37_03,
"Capitalización Individual Pensiones" = c37_04,
"Restricciones Migratorias" = c37_05,
"Educación Sexual (Padres)" = c37_06,
"Restricción a Empresas Contaminantes" = c37_07,
"Gasto Social Focalizado" = c37_08,
"Cantidad de Individuos" = cantidad_individuos
)
# Mostrar la caracterización con una tabla kable bonita
caracterizacion_tidy %>%
kbl(caption = "Caracterización de los Conglomerados Ideológicos") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = F)
| Conglomerado | Adopción Homoparental | Aborto | Rol del Estado en Educación | Capitalización Individual Pensiones | Restricciones Migratorias | Educación Sexual (Padres) | Restricción a Empresas Contaminantes | Gasto Social Focalizado | Cantidad de Individuos |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3.365796 | 2.000000 | 4.004751 | 2.546318 | 4.237530 | 2.382423 | 3.543943 | 2.703088 | 421 |
| 2 | 3.893424 | 2.909297 | 4.074830 | 3.682540 | 4.281179 | 3.977324 | 3.782313 | 3.698413 | 441 |
| 3 | 3.920981 | 4.152589 | 4.305177 | 2.629428 | 3.901907 | 2.258856 | 3.822888 | 2.795640 | 367 |
| 4 | 1.714286 | 1.864169 | 3.946136 | 3.252927 | 4.283372 | 3.950820 | 3.592506 | 3.407494 | 427 |
Conglomerado 1: Este grupo tiene un perfil ideológico más conservador en aspectos como la adopción homoparental (promedio moderado de 3.37) y el aborto (2.00), lo cual sugiere una postura más tradicional en temas sociales. De igual forma, muestran un apoyo alto a la capitalización individual de pensiones (4.00). Este grupo está compuesto por 421 individuos.
Conglomerado 2: Este conglomerado se caracteriza por posturas moderadamente favorables hacia la adopción homoparental (3.89) y el aborto (2.91). Tienen un perfil más intervencionista en temas del rol del Estado en la educación (4.07) y restricciones migratorias (4.28). Este grupo incluye 441 individuos, lo cual sugiere que representa un perfil relativamente común en la muestra.
Conglomerado 3: El tercer grupo tiene posturas más progresistas, con altos niveles de acuerdo en el aborto (4.15) y en el rol del Estado en la educación (4.31). Del mismo modo apoyan menos la capitalización individual de pensiones (2.63). En cuanto a restricciones migratorias (3.90), su postura es más favorable, pero menos extrema comparado con otros conglomerados. Este grupo contiene 367 individuos.
Conglomerado 4: Este grupo presenta el perfil más conservador entre todos los conglomerados. Los individuos de este conglomerado tienen niveles bajos de acuerdo en adopción homoparental (1.71), aborto (1.86). Muestran una mayor aceptación hacia la capitalización individual de pensiones (3.25) y el gasto social focalizado (3.41), sugiriendo una postura conservadora y pro-mercado. Este grupo está compuesto por 427 individuos.
7. Análisis de las variables más influyentes
En esta sección, realizamos un análisis de varianza (ANOVA) para cada una de las variables ideológicas con el fin de evaluar su influencia en la diferenciación de los conglomerados resultantes. El ANOVA nos permite determinar si existen diferencias significativas entre los grupos formados por el método de k-medias respecto a cada una de las opiniones encuestadas. De esta manera, podemos identificar cuáles variables juegan un papel clave en la definición de los perfiles ideológicos.
El análisis se realizó individualmente para cada una de las ocho variables, y se presenta la tabla ANOVA con el valor F y el valor p para cada una de ellas. Un valor F alto y un valor p menor a 0.05 indican que existen diferencias significativas entre los conglomerados para la variable analizada, lo cual significa que esa variable es útil para distinguir entre los diferentes perfiles ideológicos.
# ANOVA para la variable Adopción Homoparental
anova_adopcion <- aov(c37_01 ~ factor(conglomerado), data = elsoc)
summary(anova_adopcion)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 1357 452.3 694.7 <2e-16 ***
## Residuals 1652 1076 0.7
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Aborto
anova_aborto <- aov(c37_02 ~ factor(conglomerado), data = elsoc)
summary(anova_aborto)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 1298 432.6 696.6 <2e-16 ***
## Residuals 1652 1026 0.6
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Rol del Estado en Educación
anova_educacion <- aov(c37_03 ~ factor(conglomerado), data = elsoc)
summary(anova_educacion)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 28.6 9.538 14.59 2.23e-09 ***
## Residuals 1652 1080.1 0.654
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Capitalización Individual Pensiones
anova_pensiones <- aov(c37_04 ~ factor(conglomerado), data = elsoc)
summary(anova_pensiones)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 365.8 121.92 117.4 <2e-16 ***
## Residuals 1652 1716.2 1.04
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Restricciones Migratorias
anova_migrantes <- aov(c37_05 ~ factor(conglomerado), data = elsoc)
summary(anova_migrantes)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 38.8 12.93 19.87 1.18e-12 ***
## Residuals 1652 1074.6 0.65
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Educación Sexual (Padres)
anova_sexual <- aov(c37_06 ~ factor(conglomerado), data = elsoc)
summary(anova_sexual)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 1113 371.1 595.4 <2e-16 ***
## Residuals 1652 1030 0.6
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Restricción a Empresas Contaminantes
anova_contaminacion <- aov(c37_07 ~ factor(conglomerado), data = elsoc)
summary(anova_contaminacion)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 23.2 7.722 10.85 4.67e-07 ***
## Residuals 1652 1176.1 0.712
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# ANOVA para la variable Gasto Social Focalizado
anova_gasto <- aov(c37_08 ~ factor(conglomerado), data = elsoc)
summary(anova_gasto)
## Df Sum Sq Mean Sq F value Pr(>F)
## factor(conglomerado) 3 290.4 96.81 104.3 <2e-16 ***
## Residuals 1652 1533.5 0.93
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
De acuerdo con los resultados del ANOVA, las variables que muestran diferencias significativas entre los conglomerados son Adopción Homoparental, Aborto, Capitalización Individual de Pensiones, Educación Sexual (Padres) y Gasto Social Focalizado. Estas variables parecen jugar un papel clave en la diferenciación de los perfiles ideológicos dentro de la muestra. En cambio, las variables Rol del Estado en Educación, Restricciones Migratorias, y Restricción a Empresas Contaminantes no presentan diferencias significativas entre los conglomerados, lo que sugiere que estas opiniones no contribuyen de manera relevante a la definición de los grupos ideológicos identificados.
8. Visualización de Conglomerados
Finalmente, visualizaremos los conglomerados en un gráfico de dispersión utilizando dos componentes principales para entender mejor la formación de los grupos.
# Visualización de los conglomerados utilizando PCA
fviz_cluster(kmeans_result, data = elsoc_vars, geom = "point", main = "Visualización de Conglomerados - K-Means")
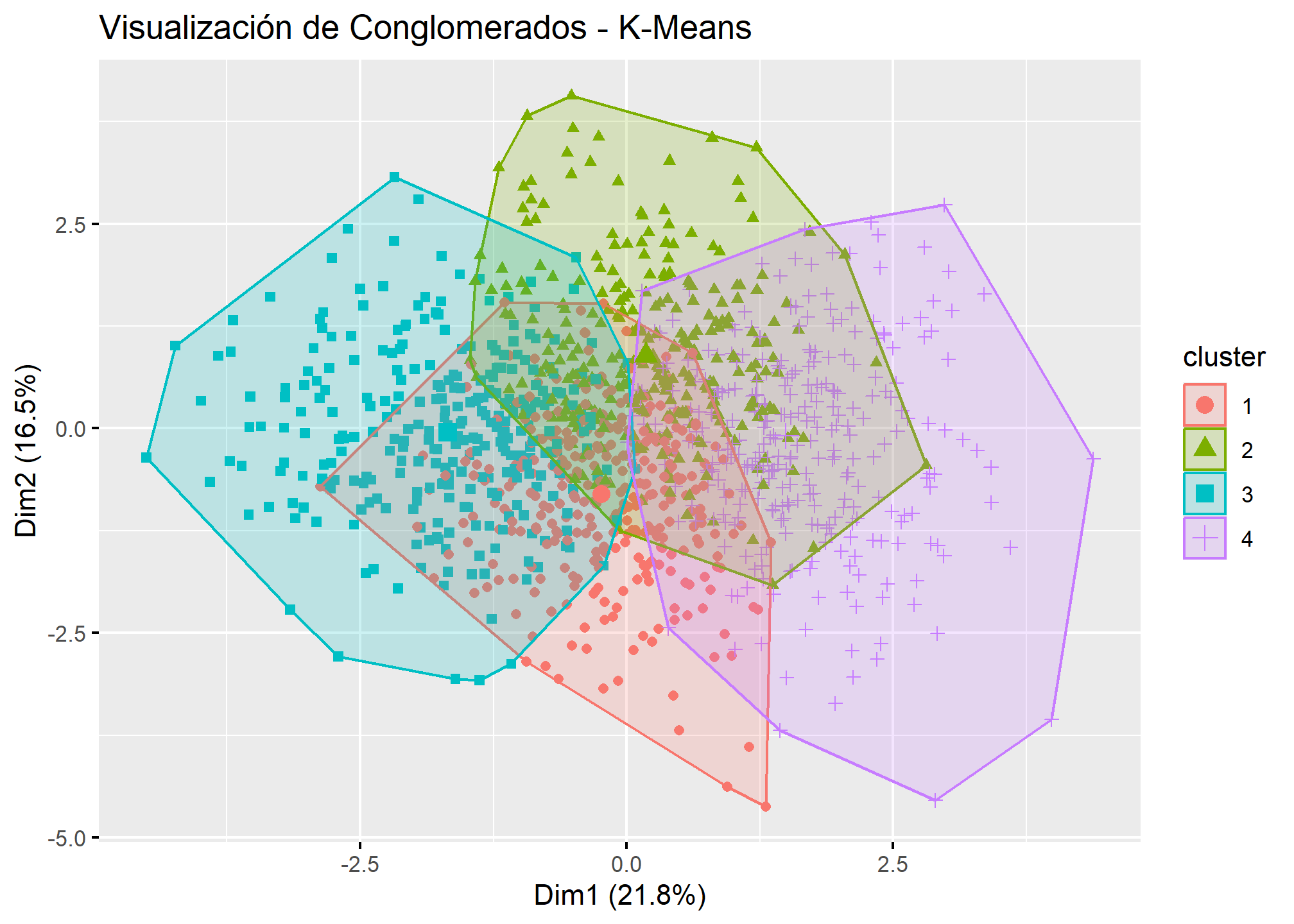
Gráfico interactivo de cluster
A continuación se presenta una herramienta que podrán usar para visualizar de mejor manera como se generan clusters a partir de k-medias.
Para acceder de mejor manera a la aplicación pueden acceder a este enlace: https://gabriel-sotomayor.shinyapps.io/Cluster/.