Análisis de regresión lineal múltiple
0. Objetivo del práctico
El objetivo de este práctico es utilizar los datos de ejercicio y pérdida de peso para entender la importancia de considerar múltiples variables predictoras en un modelo de regresión. Aplicaremos regresiones simples y múltiples, exploraremos los coeficientes, compararemos \(R^2\) y \(R^2\) ajustado, y entenderemos el valor de usar múltiples predictores conjuntamente.
1. Cargar y explorar los datos
Primero, cargamos los datos del ejercicio y pérdida de peso, que incluyen la frecuencia semanal de ejercicio, la ingesta diaria de alimentos y la pérdida semanal de peso.
pacman::p_load(dplyr, ggplot2, texreg)
# Cargar los datos
data <- data.frame(
id = 1:10,
ej = c(0, 0, 0, 2, 2, 2, 2, 4, 4, 4), # Frecuencia de ejercicio (horas semanales promedio)
cal = c(2, 4, 6, 2, 4, 6, 8, 4, 6, 8), # Ingesta diaria promedio de alimentos (100s de calorías sobre 1000)
ppeso = c(6, 2, 4, 8, 9, 8, 5, 11, 13, 9) # Pérdida de peso semanal promedio (100s de gramos)
)
# Explorar los datos
summary(data)
## id ej cal ppeso
## Min. : 1.00 Min. :0.0 Min. :2 Min. : 2.00
## 1st Qu.: 3.25 1st Qu.:0.5 1st Qu.:4 1st Qu.: 5.25
## Median : 5.50 Median :2.0 Median :5 Median : 8.00
## Mean : 5.50 Mean :2.0 Mean :5 Mean : 7.50
## 3rd Qu.: 7.75 3rd Qu.:3.5 3rd Qu.:6 3rd Qu.: 9.00
## Max. :10.00 Max. :4.0 Max. :8 Max. :13.00
2. Regresión Lineal Simple
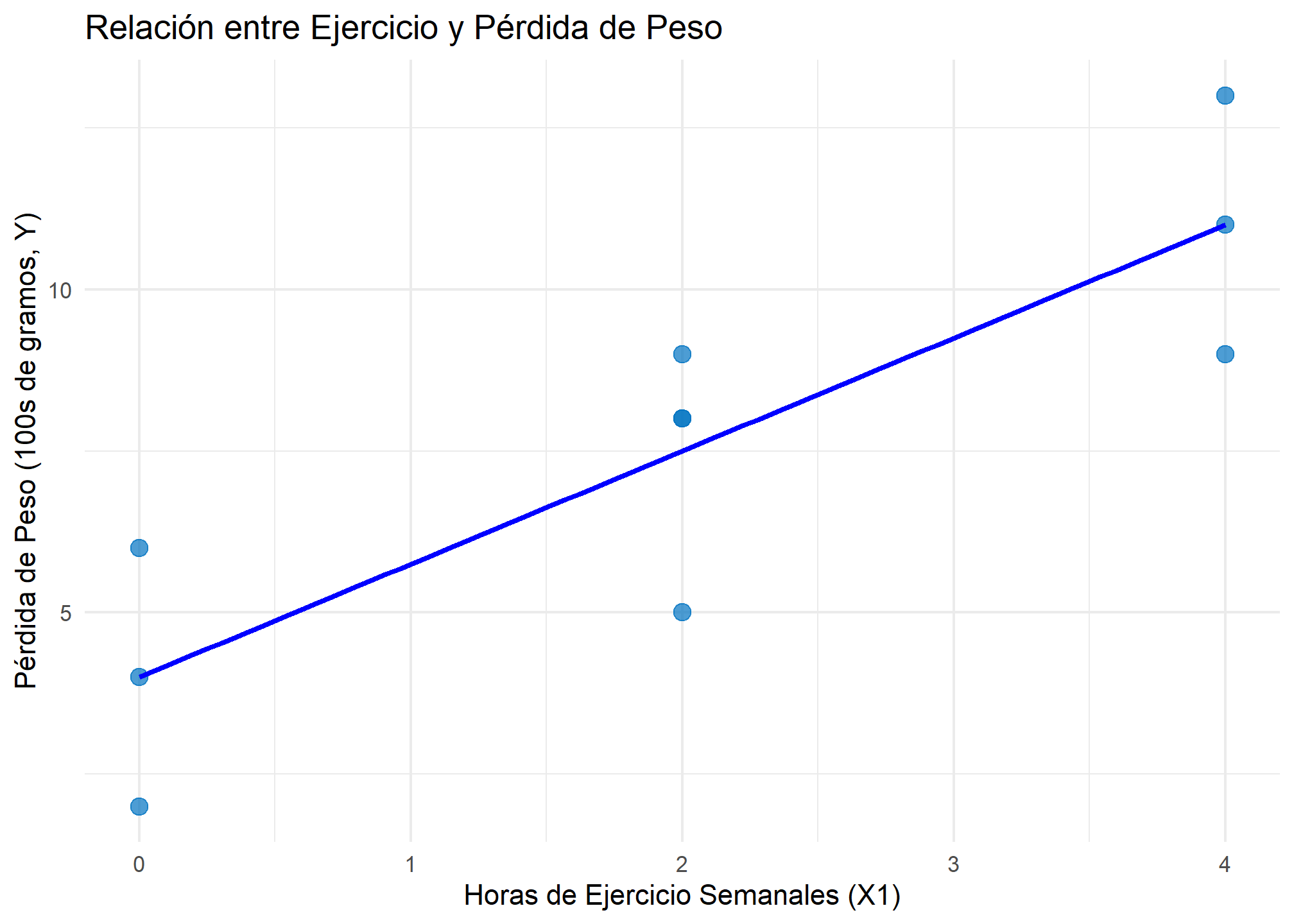
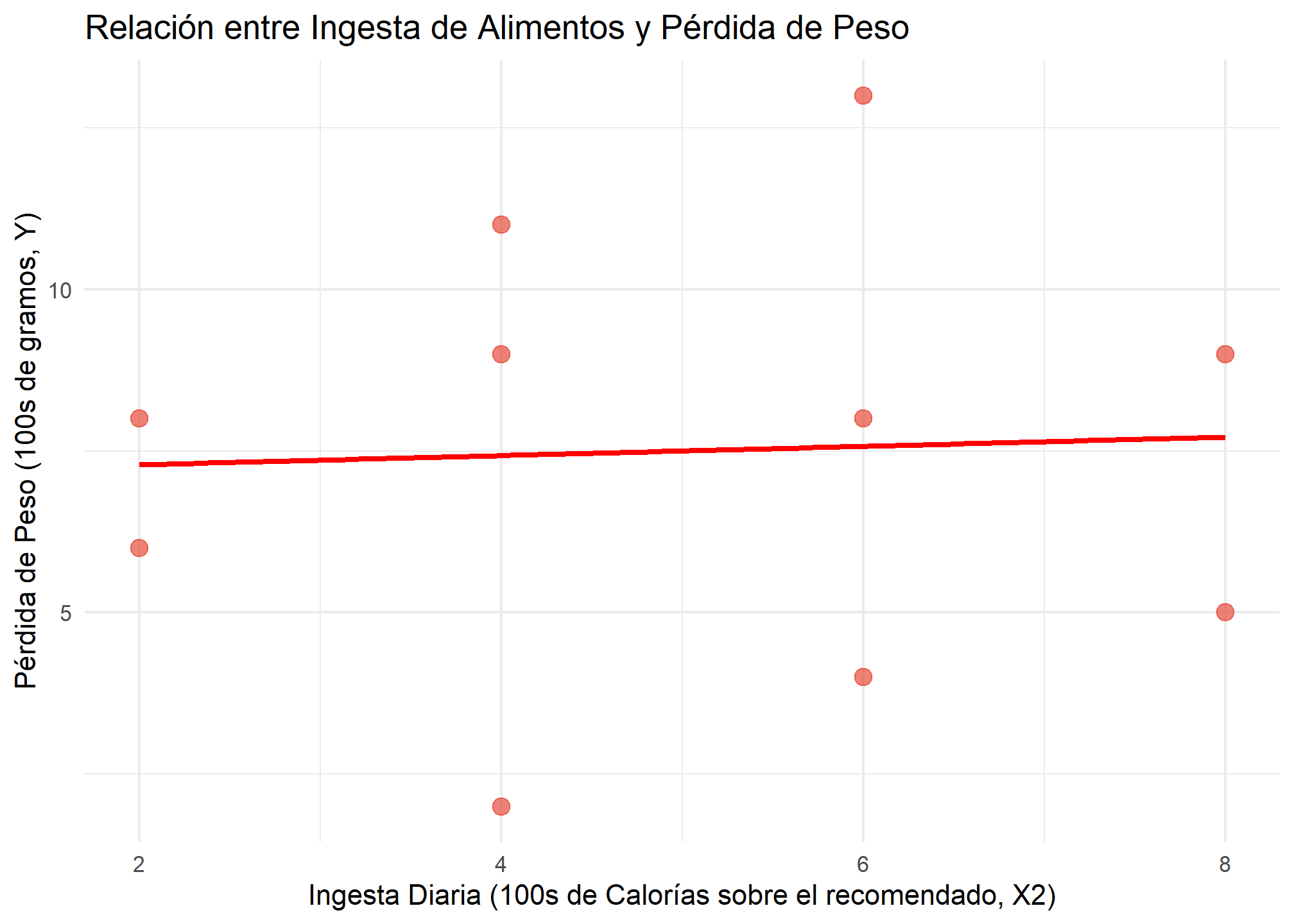
Realizamos dos regresiones lineales simples separadas: una para evaluar la relación entre el ejercicio y la pérdida de peso, y otra para evaluar la relación entre la ingesta de alimentos y la pérdida de peso.
Horas de ejercicio
# Ajustar modelo de regresión simple con ejercicio
modelo_ej <- lm(ppeso ~ ej, data = data)
# Gráfico de dispersión con línea de regresión
ggplot(data, aes(x = ej, y = ppeso)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
labs(
title = "Relación entre Ejercicio y Pérdida de Peso",
x = "Horas de Ejercicio Semanales (X1)",
y = "Pérdida de Peso (100s de gramos, Y)"
) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'
Consumo de Alimentos
# Ajustar modelo de regresión simple con ingesta de alimentos
modelo_cal <- lm(ppeso ~ cal, data = data)
# Gráfico de dispersión con línea de regresión
ggplot(data, aes(x = cal, y = ppeso)) +
geom_point(color = "#E74C3C", size = 3, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE, color = "red") +
labs(
title = "Relación entre Ingesta de Alimentos y Pérdida de Peso",
x = "Ingesta Diaria (100s de Calorías sobre el recomendado, X2)",
y = "Pérdida de Peso (100s de gramos, Y)"
) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'
3. Regresión Lineal Múltiple
Ahora ajustamos un modelo de regresión lineal múltiple para analizar cómo la frecuencia de ejercicio y la ingesta de alimentos juntas influyen en la pérdida de peso.
# Ajustar modelo de regresión múltiple
modelo_multiple <- lm(ppeso ~ ej + cal, data = data)
# Tabla de regresión múltiple en HTML
htmlreg(list(modelo_ej, modelo_cal,modelo_multiple),
custom.coef.names = c("Intercepto", "Ejercicio (X1)", "Ingesta de Alimentos (X2)"))
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| Intercepto | 4.00** | 7.14* | 6.00** |
| (0.91) | (2.92) | (1.27) | |
| Ejercicio (X1) | 1.75** | 2.00*** | |
| (0.36) | (0.33) | ||
| Ingesta de Alimentos (X2) | 0.07 | -0.50 | |
| (0.54) | (0.25) | ||
| R2 | 0.75 | 0.00 | 0.84 |
| Adj. R2 | 0.71 | -0.12 | 0.79 |
| Num. obs. | 10 | 10 | 10 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
#screenreg(list(modelo_ej, modelo_cal,modelo_multiple), custom.coef.names = c("Intercepto", "Ejercicio (X1)", "Ingesta de Alimentos (X2)"))
Los resultados de la tabla muestran los coeficientes de los modelos de regresión simple (Modelos 1 y 2) y múltiple (Modelo 3) para analizar cómo la frecuencia de ejercicio y la ingesta de alimentos afectan la pérdida de peso.
-
Modelo 1 (Ejercicio - X1): Este modelo muestra una relación positiva y significativa entre el ejercicio y la pérdida de peso, con un coeficiente de 1.75. Esto significa que por cada hora adicional de ejercicio semanal, se espera una pérdida de peso de 175 gramos. El
\(R^2\)del modelo es 0.75, lo que sugiere que el 75% de la variabilidad en la pérdida de peso puede explicarse solo por el ejercicio. -
Modelo 2 (Ingesta de Alimentos - X2): Aquí, la ingesta de alimentos no parece estar relacionada con la pérdida de peso. El coeficiente es 0.07, y el
\(R^2\)es prácticamente 0 (0.00), lo que indica que esta variable por sí sola no explica la variabilidad en la pérdida de peso. -
Modelo 3 (Ejercicio e Ingesta de Alimentos): En la regresión múltiple, observamos un comportamiento interesante. El coeficiente del ejercicio (X1) aumenta a 2.00, lo que significa que una hora adicional de ejercicio semanal se asocia con una pérdida de peso de 200 gramos, incluso después de controlar por la ingesta de alimentos. Por otro lado, el coeficiente de la ingesta de alimentos (X2) es ahora negativo (-0.50), sugiriendo que cuando se ajusta por el ejercicio, comer más se asocia con una menor pérdida de peso. Esto resalta cómo la relación parcial de una variable puede ser diferente en un modelo múltiple comparado con un modelo simple.
El modelo ajustado de regresión para la pérdida de peso es:
$$ \text{Pérdida de peso} = 6.00 + 2.00 \times \text{Horas de ejercicio} - 0.50 \times \text{Calorías consumidas sobre el recomendado} $$
4. Diferencia entre \(R^2\) y \(R^2\) ajustado
El \(R^2\) indica qué porcentaje de la variabilidad en la variable dependiente (pérdida de peso) es explicado por las variables independientes (ejercicio e ingesta de alimentos).
-
\(R^2\): Se calcula como la proporción de la varianza explicada por el modelo. Sin embargo, puede aumentar al agregar más variables, incluso si esas variables no son significativas. -
\(R^2\)ajustado: Penaliza por el número de variables incluidas en el modelo. Esto significa que solo aumentará si las variables adicionales realmente mejoran el modelo.
En el Modelo 3 (regresión múltiple), el \(R^2\) aumenta a 0.84, lo que sugiere que el 84% de la variabilidad en la pérdida de peso puede explicarse por la combinación de ejercicio e ingesta de alimentos. Esto es un incremento significativo en comparación con el \(R^2\) de 0.75 cuando solo se consideraba el ejercicio. A pesar de que la ingesta de alimentos por sí sola no parecía explicar la variabilidad (como se ve en el Modelo 2, donde \(R^2 = 0.00\)), al incluirla en el modelo múltiple junto con el ejercicio, mejora la capacidad explicativa del modelo.
El \(R^2\) ajustado es más conservador, con un valor de 0.79 en el modelo múltiple, lo que sigue siendo una mejora significativa comparado con los modelos simples. Esto indica que la adición de la ingesta de alimentos mejora el modelo, aunque de manera moderada, dado que la variable no es estadísticamente significativa por sí sola.
5. Ejercicio con la Base de Brecha Salarial
Con los datos de brecha salarial de género, promedio de años de escolaridad y proporción de población rural, ajusta un modelo de regresión lineal múltiple para analizar cómo estas dos variables influyen en la brecha salarial. Completa los siguientes pasos:
-
Ajusta una regresión simple con el promedio de años de escolaridad como predictor.
-
Ajusta otra regresión simple con la proporción de población rural como predictor.
-
Ajusta un modelo de regresión múltiple con ambas variables.
-
Compara los coeficientes, el
\(R^2\)y el\(R^2\)ajustado entre los modelos.
# Cargar los datos de brecha salarial
datos_brecha <- readRDS(url("https://github.com/GabrielSotomayorl/aadi2024/raw/main/content/example/input/data/datos.rds")) %>%
select(comuna, ing_prom_hombre, ing_prom_mujer, prom_esc = promedio_anios_escolaridad25_2017, prop_rural_2020) %>%
mutate(brecha = (ing_prom_hombre - ing_prom_mujer) / ing_prom_hombre * 100)
# Ajustar modelos y comparar
modelo_brecha_esc <- lm(brecha ~ prom_esc, data = datos_brecha)
modelo_brecha_rural <- lm(brecha ~ prop_rural_2020, data = datos_brecha)
modelo_brecha_multiple <- lm() #completar
# Comparar modelos
screenreg(list(), custom.coef.names = c("Intercepto", "Promedio de escolaridad", "Proporción pob. rural")) #completar