Diagnosticos y supuestos de modelos de regresión
0. Objetivo del Práctico
El presente práctico tiene como objetivo aprender a evaluar los supuestos y realizar diagnósticos de un modelo de regresión lineal múltiple utilizando la Encuesta Nacional de Uso del Tiempo 2015 (ENUT). A través del análisis de los datos, construiremos un modelo para explicar el tiempo dedicado al trabajo doméstico no remunerado (TDNR) en función de diversas características sociodemográficas. Además, se enseñará cómo identificar y tratar observaciones influyentes, verificar la linealidad, homocedasticidad, multicolinealidad y normalidad de los residuos, asegurando así la validez de nuestras inferencias.
1. Carga y preparación de la base de datos.
La Encuesta Nacional de Uso del Tiempo 2015 (ENUT) tiene como finalidad proveer información detallada sobre cómo la población distribuye su tiempo entre diversas actividades, poniendo un énfasis particular en aquellas relacionadas con el trabajo no remunerado. Esta encuesta permite visibilizar el trabajo que realizan las personas en sus hogares, ya sea en labores domésticas o en el cuidado de los integrantes de la familia, así como actividades de apoyo a otros hogares, la comunidad y voluntariado.
El propósito principal de la ENUT es cuantificar este tipo de trabajo no remunerado, que a menudo no se reconoce como “trabajo” en sentido formal, pero que representa una parte crucial del tiempo y esfuerzo diario de las personas. Medir estas actividades permite evidenciar que el tiempo dedicado a ellas puede ser comparable e incluso superior al del trabajo remunerado. De esta manera, la ENUT contribuye a una comprensión más completa del concepto de trabajo, considerando tanto las actividades remuneradas como las no remuneradas.
En este práctico, trabajaremos con la variable de Trabajo Doméstico No Remunerado (TDNR), modelando cómo diferentes características sociodemográficas influyen en el tiempo dedicado a estas actividades.
library(haven)
library(dplyr)
# URL ajustada para descargar la versión raw del archivo
url <- "https://github.com/GabrielSotomayorl/aadi2024/raw/main/content/example/input/data/enut.rds"
# Creamos un archivo temporal para almacenar el .rds descargado
temp <- tempfile()
# Descargamos el archivo .rds directamente
download.file(url, temp, mode = "wb")
# Cargamos el archivo .rds con readRDS()
enut <- readRDS(temp)
# Eliminamos el archivo temporal
unlink(temp); remove(temp)
2. Construcción de un modelo de regresión lineal múltiple
Variables a utilizar
- tdnr_dt: Tiempo dedicado al trabajo doméstico no remunerado en un día tipo (en horas).
- c13_1_1: Género de la persona encuestada (1 = Hombre, 2 = Mujer).
- c14_1_1: Edad de la persona encuestada.
- n2_1_1: Presencia de menores de 0 a 4 años en el hogar (1 = Sí, 2 = No).
- n3_1_1: Presencia de niños/niñas de 5 a 14 años en el hogar (1 = Sí, 2 = No).
Estas variables se seleccionaron porque se espera que tanto el género como la presencia de menores en el hogar y la edad puedan influir significativamente en la cantidad de tiempo dedicado al trabajo doméstico no remunerado.
enut <- enut %>%
filter(!is.na(tdnr_dt))
library(texreg)
## Version: 1.38.6
## Date: 2022-04-06
## Author: Philip Leifeld (University of Essex)
##
## Consider submitting praise using the praise or praise_interactive functions.
## Please cite the JSS article in your publications -- see citation("texreg").
dom<-lm(tdnr_dt~factor(c13_1_1)+c14_1_1+factor(n2_1_1, levels = c(2,1))+factor(n3_1_1, levels = c(2,1)),data=enut,weights = wgt2)
#screenreg(list(dom), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a años (ref. No)"))
htmlreg(list(dom), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a 14 años (ref. No)"))
| Model 1 | |
|---|---|
| Intercepto | 0.37*** |
| (0.05) | |
| Mujer (ref.hombre) | 1.92*** |
| (0.03) | |
| Edad | 0.03*** |
| (0.00) | |
| Presencia de menores de 0 a 4 años (ref. No) | 0.19*** |
| (0.04) | |
| Presencia de nna de 5 a 14 años (ref. No) | 0.26*** |
| (0.04) | |
| R2 | 0.19 |
| Adj. R2 | 0.19 |
| Num. obs. | 20595 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Interpretación de los Coeficientes
A continuación, se presenta la interpretación detallada de los coeficientes del modelo de regresión lineal múltiple estimado, considerando el control estadístico y la significación de cada uno de ellos.
-
Intercepto: El intercepto ($\beta_0 = 0.37$,
\(p < 0.001\)) indica el valor esperado del tiempo dedicado al trabajo doméstico no remunerado (TDNR) en horas cuando todas las variables independientes son iguales a cero. En este contexto, representa a un hombre sin menores en el hogar y con edad cero (hipotético). Aunque este valor no es empíricamente significativo en un sentido práctico, es importante para el ajuste del modelo. -
Género (Mujer, ref. hombre): El coeficiente asociado al género ($\beta_1 = 1.92$,
\(p < 0.001\)) sugiere que, en promedio, las mujeres dedican 1.92 horas más al trabajo doméstico no remunerado que los hombres, controlando por edad y la presencia de menores en el hogar. Este resultado es estadísticamente significativo, lo cual indica que el género tiene un efecto importante en la cantidad de tiempo dedicado al TDNR. -
Edad: El coeficiente de la edad ($\beta_2 = 0.03$,
\(p < 0.001\)) indica que, por cada año adicional de edad, se espera un aumento promedio de 0.03 horas en el tiempo dedicado al TDNR, manteniendo constantes las demás variables del modelo. Este efecto es pequeño pero estadísticamente significativo, sugiriendo que el tiempo dedicado al trabajo doméstico no remunerado tiende a aumentar levemente con la edad. -
Presencia de menores de 0 a 4 años (ref. No): El coeficiente correspondiente a la presencia de menores de 0 a 4 años en el hogar ($\beta_3 = 0.19$,
\(p < 0.001\)) indica que tener un menor de esta edad en el hogar está asociado con un aumento promedio de 0.19 horas en el tiempo dedicado al TDNR, en comparación con aquellos hogares sin menores de esa edad. Este efecto también es estadísticamente significativo, lo cual sugiere que la presencia de menores pequeños tiene un impacto relevante en el trabajo doméstico. -
Presencia de NNA de 5 a 14 años (ref. No): El coeficiente para la presencia de niños/niñas de 5 a 14 años ($\beta_4 = 0.26$,
\(p < 0.001\)) indica que tener menores de esta edad en el hogar está asociado con un incremento promedio de 0.26 horas en el tiempo dedicado al TDNR, en comparación con hogares sin menores de 5 a 14 años. Este resultado es igualmente estadísticamente significativo, lo cual respalda la idea de que la presencia de niños en el hogar aumenta la carga de trabajo doméstico.
En resumen, todos los coeficientes estimados son estadísticamente significativos (p < 0.001), lo que sugiere que las variables género, edad y la presencia de menores en el hogar tienen una relación significativa con el tiempo dedicado al trabajo doméstico no remunerado. Estos resultados destacan la importancia de los factores sociodemográficos en la distribución del trabajo no remunerado.
3. Diagnóstico del Modelo
Los diagnósticos del modelo nos permiten evaluar si el modelo cumple con los supuestos fundamentales de la regresión lineal, y si hay observaciones que están afectando desproporcionadamente el ajuste del modelo.
Diagnóstico Exploratorio del Modelo con plot()
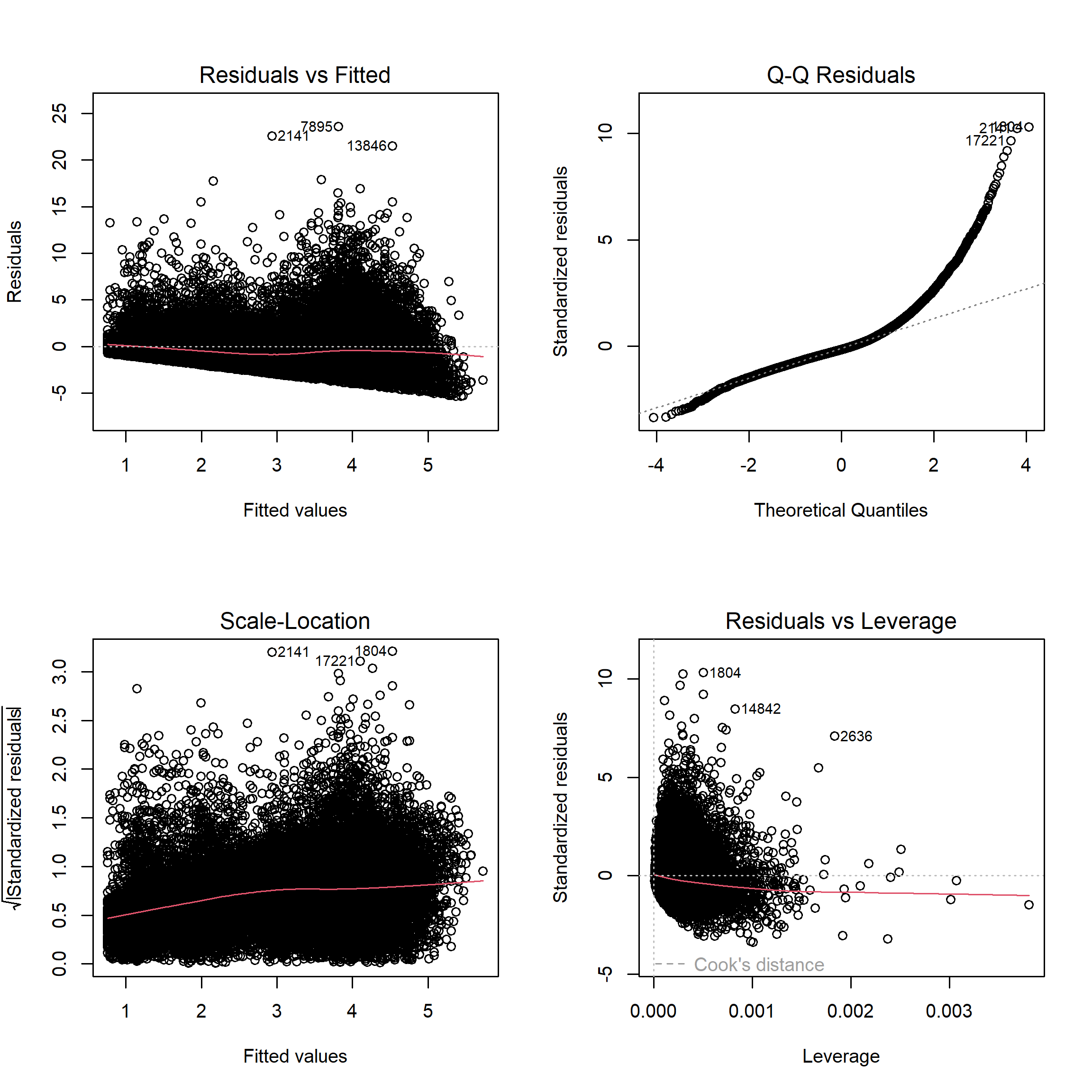
R proporciona una forma rápida de generar varios gráficos de diagnóstico del modelo utilizando la función plot(). Esta función genera cuatro gráficos clave para evaluar visualmente los supuestos del modelo de regresión lineal. A continuación, se muestran los gráficos generados y su interpretación.
# Graficos de diagnostico basicos
par(mfrow = c(2, 2))
plot(dom)
par(mfrow = c(1, 1))
-
Gráfico de Residuos vs. Valores Ajustados: Este gráfico permite evaluar la linealidad y homocedasticidad del modelo. Si el supuesto de linealidad se cumple, no deberíamos observar ningún patrón claro en la dispersión de los residuos. Una varianza constante en los residuos (homocedasticidad) se refleja en una distribución uniforme de los puntos sin formar un patrón cónico.
-
Gráfico Q-Q: Este gráfico compara los residuos estandarizados con una distribución normal teórica. Si los puntos siguen la línea diagonal, se puede asumir que los residuos se distribuyen normalmente. Desviaciones significativas indicarían una violación de la normalidad de los residuos.
-
Escala de Localización (Scale-Location): Este gráfico permite verificar la homocedasticidad de los residuos. Se espera una línea horizontal con puntos aleatoriamente dispersos. Si hay un patrón claro, podría indicar que la varianza de los residuos no es constante.
-
Gráfico de Residuos Estandarizados vs. Leverage: Este gráfico es útil para identificar observaciones influyentes que podrían afectar los resultados del modelo. Los puntos fuera de las bandas de Cook tienen una influencia considerable y podrían ser problemáticos para el ajuste del modelo.
Estos gráficos permiten una exploración rápida y visual de los supuestos fundamentales del modelo antes de proceder con análisis más detallados.
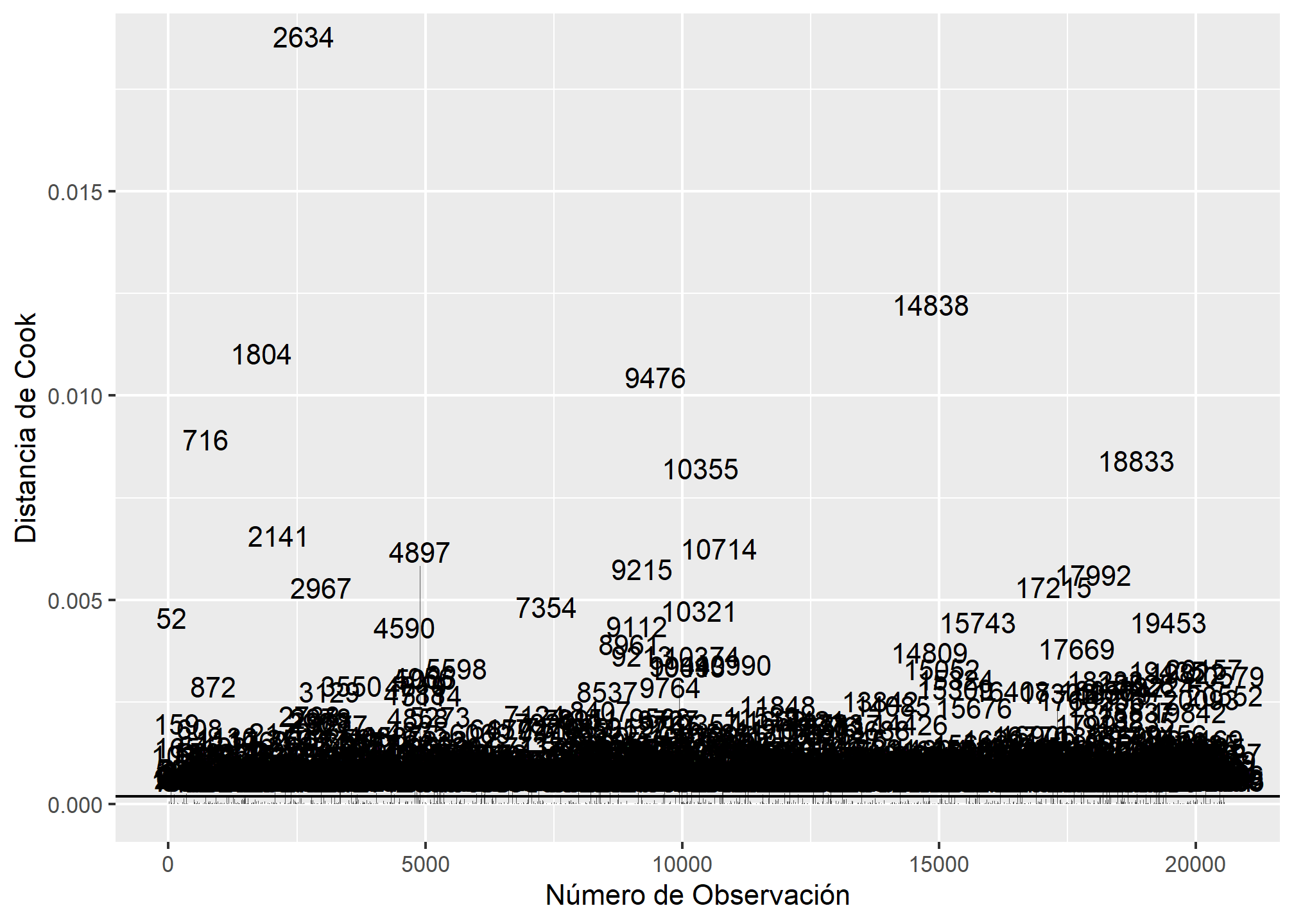
3.1 Casos Influyentes: Distancia de Cook
La Distancia de Cook mide el impacto de cada observación en los coeficientes del modelo. Se calcula un punto de corte con la fórmula 4/(n-k-1), donde n es el número de observaciones y k el número de parámetros del modelo.
library(broom)
library(ggplot2)
library(dplyr)
n <- nobs(dom)
k <- length(coef(dom))
dcook <- 4/(n-k-1) # Punto de corte de Cook's D
# Crear tabla con residuos y Cook's D
final <- broom::augment_columns(dom, data = enut)
final$id <- as.numeric(row.names(final))
# Gráfico de la distancia de Cook
ggplot(final, aes(id, .cooksd)) +
geom_bar(stat = "identity", position = "identity") +
xlab("Número de Observación") + ylab("Distancia de Cook") +
geom_hline(yintercept = dcook) +
geom_text(aes(label = ifelse((.cooksd > dcook), id, "")), vjust = -0.2, hjust = 0.5)
# Filtrar observaciones influyentes
ident <- final %>% filter(.cooksd > dcook)
base2 <- final %>% filter(!(id %in% ident$id))
Las observaciones que superan el punto de corte son consideradas influyentes, ya que tienen un impacto desproporcionado en el ajuste del modelo. Generaremos una base de datos sin los casos influyentes para observar como se comporta el modelo al estimarlo sin estos. A pesar de lo anterior es improtnate considerar que en la práctica solo debemos removerlos sin tenemos alguna buena razón para creer que estos se deben a un error de medición o algún otro problema, ya que de lo contrariop estaremos forzando el buen ajuste del modelo.
dom2<-lm(tdnr_dt~factor(c13_1_1)+c14_1_1+factor(n2_1_1, levels = c(2,1))+factor(n3_1_1, levels = c(2,1)),data=base2,weights = wgt2)
#screenreg(list(dom, dom2), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a años (ref. No)"), custom.model.names = c("Con atípicos", "Sin atípicos"))
htmlreg(list(dom, dom2), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a 14 años (ref. No)"), custom.model.names = c("Con atípicos", "Sin atípicos"))
| Con atípicos | Sin atípicos | |
|---|---|---|
| Intercepto | 0.37*** | 0.17*** |
| (0.05) | (0.04) | |
| Mujer (ref.hombre) | 1.92*** | 1.84*** |
| (0.03) | (0.03) | |
| Edad | 0.03*** | 0.03*** |
| (0.00) | (0.00) | |
| Presencia de menores de 0 a 4 años (ref. No) | 0.19*** | 0.14*** |
| (0.04) | (0.03) | |
| Presencia de nna de 5 a 14 años (ref. No) | 0.26*** | 0.24*** |
| (0.04) | (0.03) | |
| R2 | 0.19 | 0.29 |
| Adj. R2 | 0.19 | 0.29 |
| Num. obs. | 20595 | 19215 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
3.2 Linealidad: Valores Ajustados vs Residuos
Para que el modelo de regresión lineal sea válido, la relación entre los predictores y la respuesta debe ser aproximadamente lineal. Evaluamos la linealidad mediante un gráfico de los residuos vs valores ajustados.
# Verificar la linealidad mediante un gráfico de residuos vs valores ajustados
ggplot(dom, aes(.fitted, .resid)) +
geom_point() +
geom_hline(yintercept = 0) +
geom_smooth(se = TRUE)
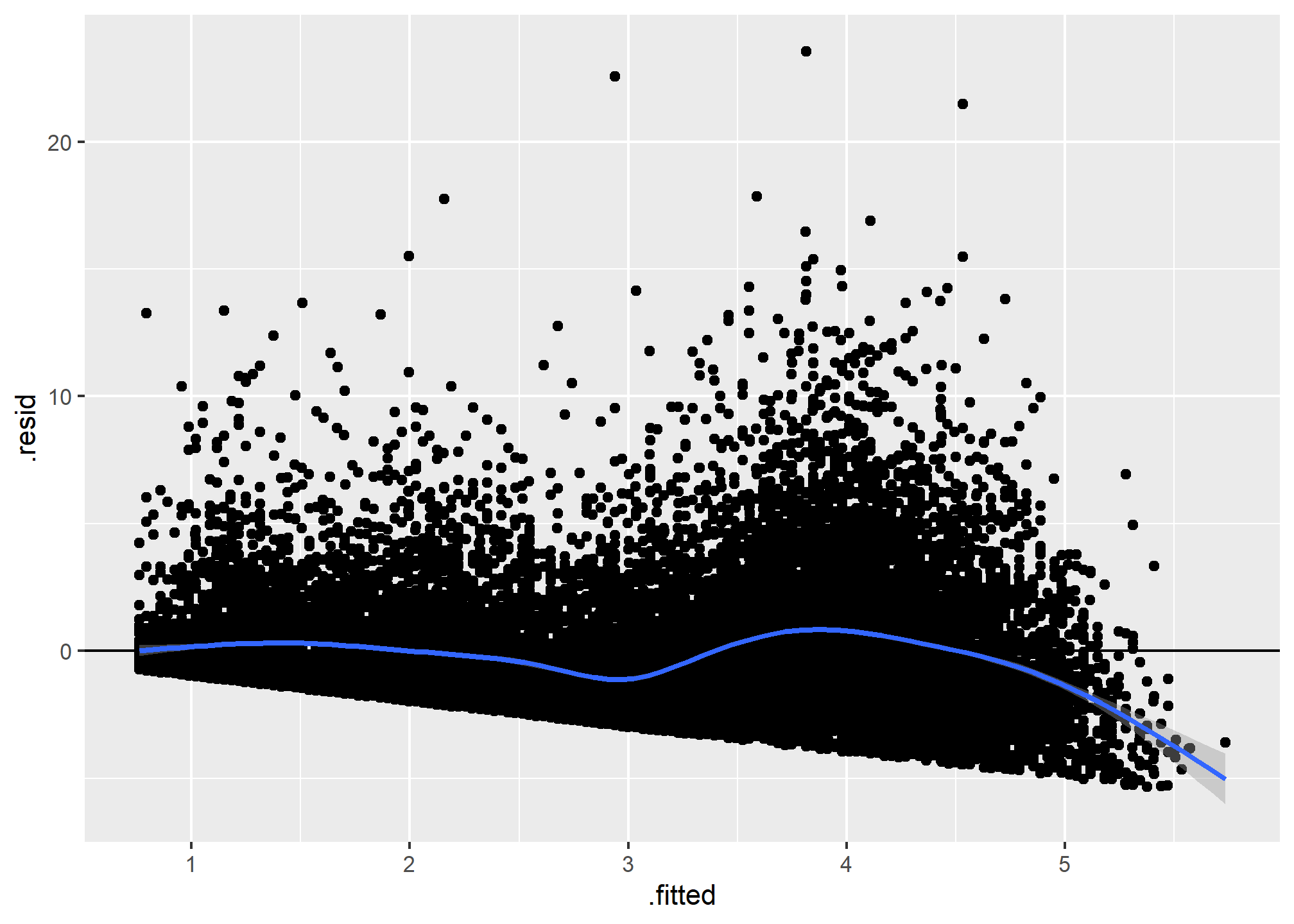
Un patrón no aleatorio en este gráfico podría indicar una violación del supuesto de linealidad. Si observamos un patrón claro, como una curva o una forma en U, puede ser una señal de que la relación entre las variables independientes y la variable dependiente no es estrictamente lineal. Esto sugiere que la relación no se está capturando correctamente con un modelo lineal simple, lo cual podría afectar la validez del modelo y la interpretación de los coeficientes.
Podemos explorar de igual modo la existencia de relaciones no lineales a partir de gráficos de dispersión. Tomemos como ejemplo la relación entre tiempo dedicado al trabajo doméstico y edad.
ggplot(enut, aes(x = c14_1_1, y = tdnr_dt)) +
geom_point(alpha = 0.6, color = "#2c3e50") + # Puntos con transparencia para mejor visualización
geom_smooth(method = "loess", se = TRUE, color = "#e74c3c", fill = "#e74c3c", alpha = 0.2) + # Línea de ajuste suavizada
labs(
title = "Tiempo Dedicado al Trabajo Doméstico versus Edad",
x = "Edad",
y = "Tiempo Dedicado al Trabajo Doméstico (horas)",
caption = "Fuente: ENUT"
) +
theme_minimal(base_size = 15) + # Tema minimalista y texto más grande
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 20), # Título centrado y en negrita
axis.title = element_text(face = "bold"), # Ejes en negrita
panel.grid.major = element_line(color = "#dfe6e9") # Líneas de cuadrícula más suaves
)
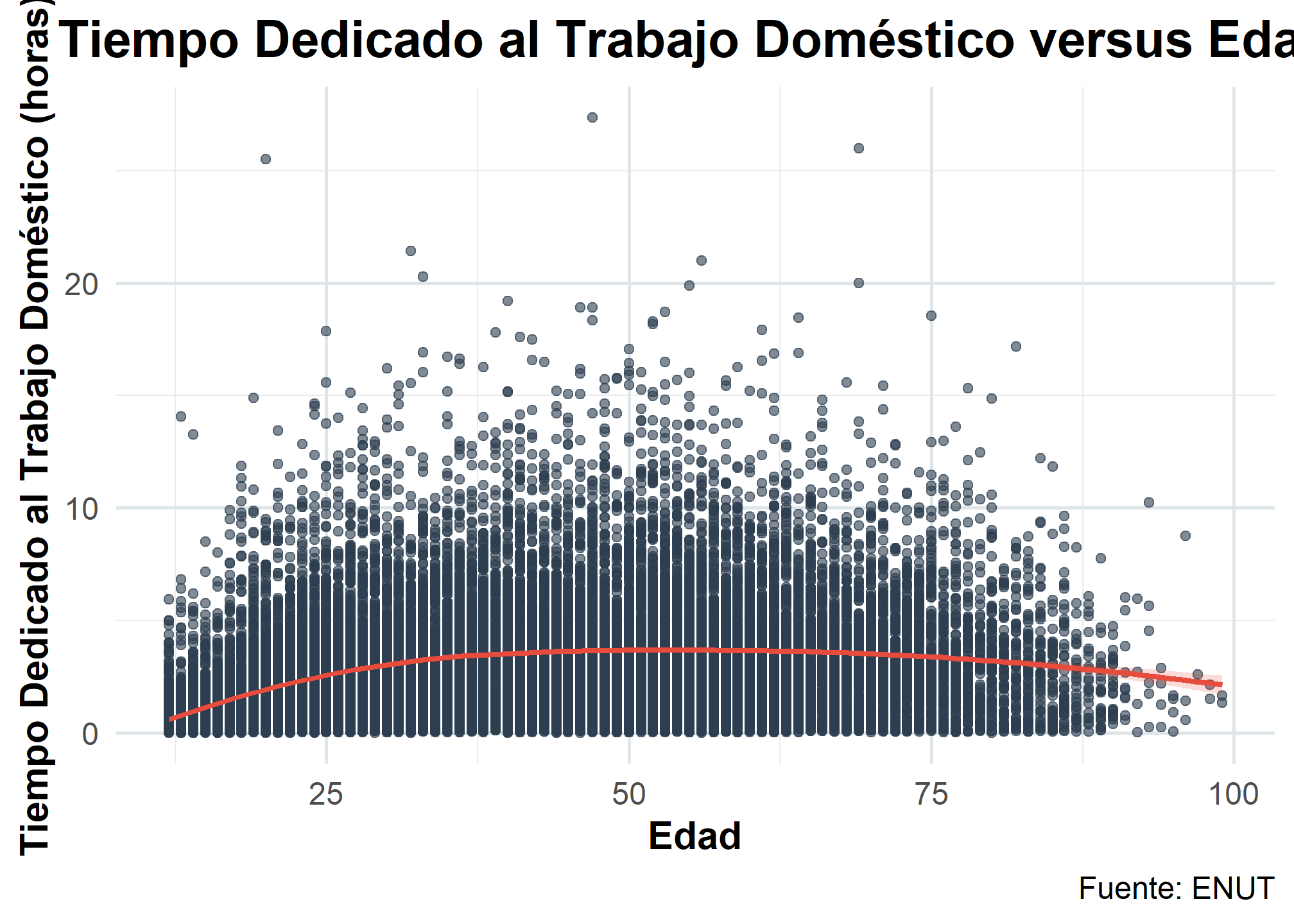
En este gráfico se observa una relación no lineal, donde el tiempo dedicado al trabajo doméstico aumenta con la edad hasta un punto, y luego disminuye. Este patrón en forma de arco no puede ser representado correctamente por un modelo lineal simple.
Para integrar esta relación no lineal en el modelo, podemos agregar una variable transformada, en este caso, la edad al cuadrado (c14_1_1^2). Esto nos permitirá modelar la relación de manera más precisa y capturar la curvatura observada.
En este modelo ajustado (dom3), hemos añadido un término cuadrático (I(c14_1_1 * c14_1_1)), lo cual permite que la relación entre edad y tiempo dedicado al trabajo doméstico sea curvilínea. Esto significa que el modelo ahora puede capturar tanto el crecimiento inicial del tiempo dedicado al trabajo doméstico como la eventual disminución conforme las personas envejecen.
dom3<-lm(tdnr_dt~factor(c13_1_1)+c14_1_1+I(c14_1_1*c14_1_1)+factor(n2_1_1, levels = c(2,1))+factor(n3_1_1, levels = c(2,1)),data=enut,weights = wgt2)
#screenreg(list(dom3, dom), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Edad al cuadrado", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a años (ref. No)"))
htmlreg(list(dom3, dom), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Edad al cuadrado", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a 14 años (ref. No)"))
| Model 1 | Model 2 | |
|---|---|---|
| Intercepto | -1.55*** | 0.37*** |
| (0.09) | (0.05) | |
| Mujer (ref.hombre) | 1.91*** | 1.92*** |
| (0.03) | (0.03) | |
| Edad | 0.14*** | 0.03*** |
| (0.00) | (0.00) | |
| Edad al cuadrado | -0.00*** | |
| (0.00) | ||
| Presencia de menores de 0 a 4 años (ref. No) | 0.13** | 0.19*** |
| (0.04) | (0.04) | |
| Presencia de nna de 5 a 14 años (ref. No) | 0.15*** | 0.26*** |
| (0.04) | (0.04) | |
| R2 | 0.22 | 0.19 |
| Adj. R2 | 0.22 | 0.19 |
| Num. obs. | 20595 | 20595 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
3.3 Homocedasticidad: Test de Breusch-Pagan
La homocedasticidad es un supuesto clave en la regresión lineal, que implica que los residuos del modelo tienen una varianza constante a lo largo de todos los valores ajustados. Esto asegura que la dispersión de los errores sea similar en todos los niveles de la variable dependiente. Esto puede observarse a partir del gráfico de Residuos vs. Valores Ajustados que vimos anteriormente. Evaluamos este supuesto mediante el test de Breusch-Pagan.
library(car)
car::ncvTest(dom)
## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 1149.659, Df = 1, p = < 2.22e-16
Un p-valor bajo sugiere que la varianza de los residuos no es constante, lo que indica heterocedasticidad. Dado que el p-valor es extremadamente bajo, rechazamos la hipótesis nula de homocedasticidad. Esto indica que existe evidencia estadística de heterocedasticidad en el modelo, lo cual significa que la varianza de los residuos no es constante. Este resultado tiene implicaciones importantes, ya que la heterocedasticidad puede afectar los errores estándar de los coeficientes, haciendo que las pruebas de significancia estadística sean poco confiables.
Corrección de Heterocedasticidad con Errores Estándar Robustos
Una solución cuando se detecta heterocedasticidad es utilizar errores estándar robustos, que ajustan los intervalos de confianza y las pruebas de significancia para tener en cuenta la variabilidad no constante en los residuos.
# Librerías necesarias para utilizar errores estándar robustos
library(sandwich)
library(lmtest)
# Ajuste del modelo utilizando errores estándar robustos
robust_results <- coeftest(dom, vcov = vcovHC(dom, type = "HC1"))
#screenreg(list(dom, robust_results), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a 14 años (ref. No)"),custom.model.names = c("Modelo original", "Modelo con errores estándares robustos"))
htmlreg(list(dom, robust_results), custom.coef.names = c("Intercepto", "Mujer (ref.hombre)", "Edad", "Presencia de menores de 0 a 4 años (ref. No)", "Presencia de nna de 5 a 14 años (ref. No)"),
custom.model.names = c("Modelo original", "Modelo con errores estándares robustos"))
| Modelo original | Modelo con errores estándares robustos | |
|---|---|---|
| Intercepto | 0.37*** | 0.37*** |
| (0.05) | (0.05) | |
| Mujer (ref.hombre) | 1.92*** | 1.92*** |
| (0.03) | (0.04) | |
| Edad | 0.03*** | 0.03*** |
| (0.00) | (0.00) | |
| Presencia de menores de 0 a 4 años (ref. No) | 0.19*** | 0.19*** |
| (0.04) | (0.05) | |
| Presencia de nna de 5 a 14 años (ref. No) | 0.26*** | 0.26*** |
| (0.04) | (0.04) | |
| R2 | 0.19 | |
| Adj. R2 | 0.19 | |
| Num. obs. | 20595 | |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
vcovHC(): Calcula la matriz de covarianza robusta del modelo, dondetype = "HC1"es una corrección común para heterocedasticidad (similar a la corrección de White).coeftest(): Realiza las pruebas de significancia con la matriz de covarianza robusta, proporcionando coeficientes ajustados y errores estándar robustos.
3.4 Multicolinealidad: VIF (Factor de Inflación de Varianza)
La multicolinealidad se refiere a la alta correlación entre predictores, lo cual dificulta determinar sus efectos individuales. Se evalúa utilizando el Factor de Inflación de Varianza (VIF).
VIF (variance inflation factor) es una medida de la multicolinealidad en un modelo de regresión. Mide el grado en que los predictores están correlacionados entre sí. Un valor VIF de 1 indica que no hay multicolinealidad, mientras que un valor VIF mayor que 1 indica que los predictores están correlacionados y se inflan los errores estándar de los coeficientes. Los valores comúnmente aceptados para el VIF son menores de 2.5 o 5. Valores mayores a estos pueden indicar problemas de multicolinealidad en el modelo.
car::vif(dom) # Se espera que no existan valores mayores a 2.5
## factor(c13_1_1) c14_1_1
## 1.012860 1.091084
## factor(n2_1_1, levels = c(2, 1)) factor(n3_1_1, levels = c(2, 1))
## 1.069695 1.071940
3.5 Normalidad de los Residuos
Para que las inferencias del modelo sean válidas, los residuos deben estar distribuidos normalmente. Evaluamos esto mediante un histograma de los residuos y un gráfico Q-Q.
Histograma de los Residuos
# Verificar la normalidad de los residuos mediante un histograma
hist(dom$residuals,
main = "Histograma de Residuos",
xlab = "Residuos",
col = "#ADD8E6",
border = "black")
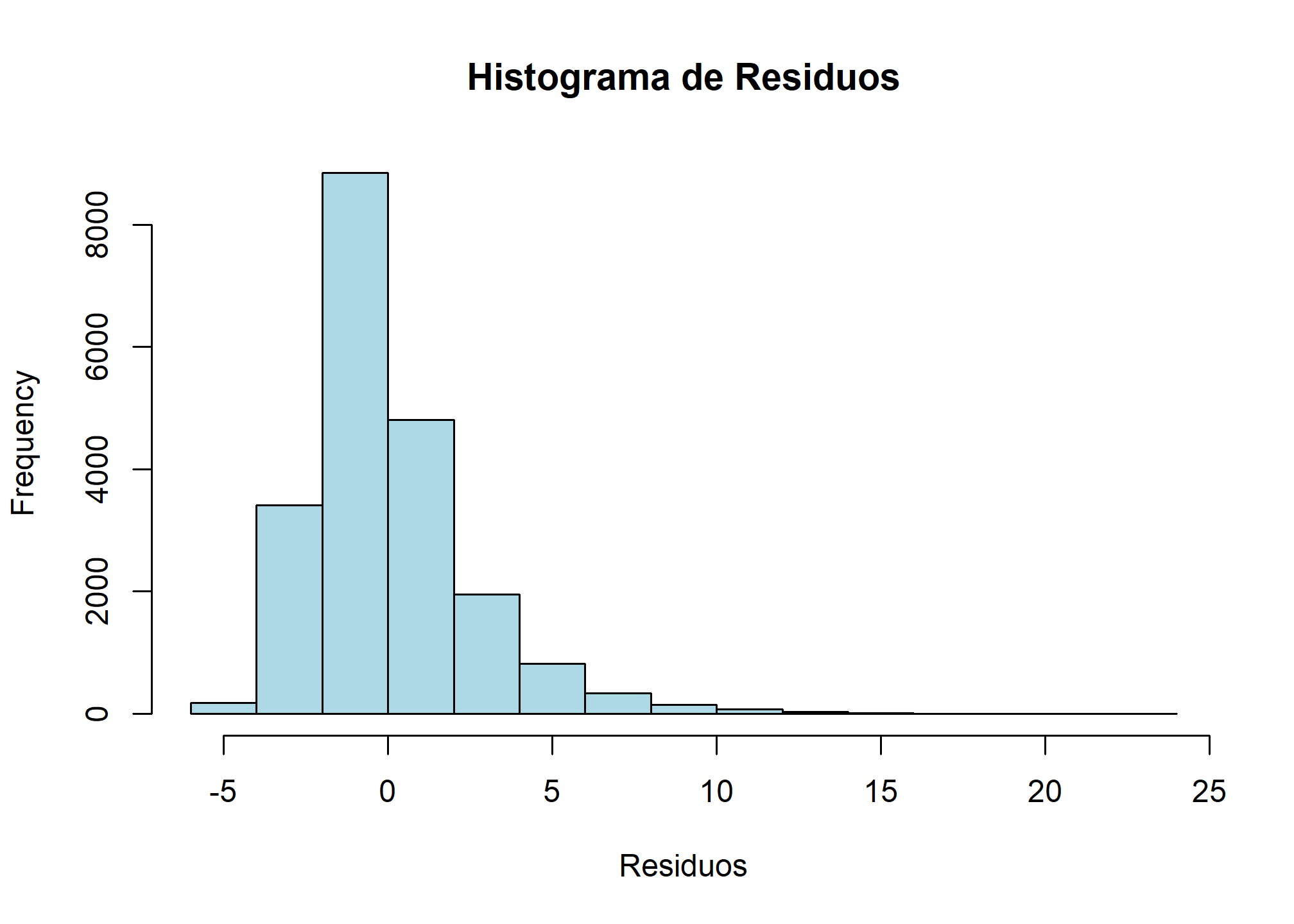
Un histograma es una manera efectiva de visualizar la distribución de los residuos. Si los residuos siguen una distribución aproximadamente normal, deberíamos ver una forma bell-shaped (en forma de campana). Si los residuos no siguen una distribución normal, las inferencias del modelo podrían estar sesgadas.
Gráfico Q-Q de los Residuos
Otra forma común de evaluar la normalidad de los residuos es mediante un gráfico Q-Q (Quantile-Quantile), que compara los cuantiles de los residuos con los cuantiles de una distribución normal teórica.
# Gráfico Q-Q para evaluar la normalidad de los residuos
qqnorm(dom$residuals,
main = "Gráfico Q-Q de Residuos")
qqline(dom$residuals,
col = "red",
lwd = 2)
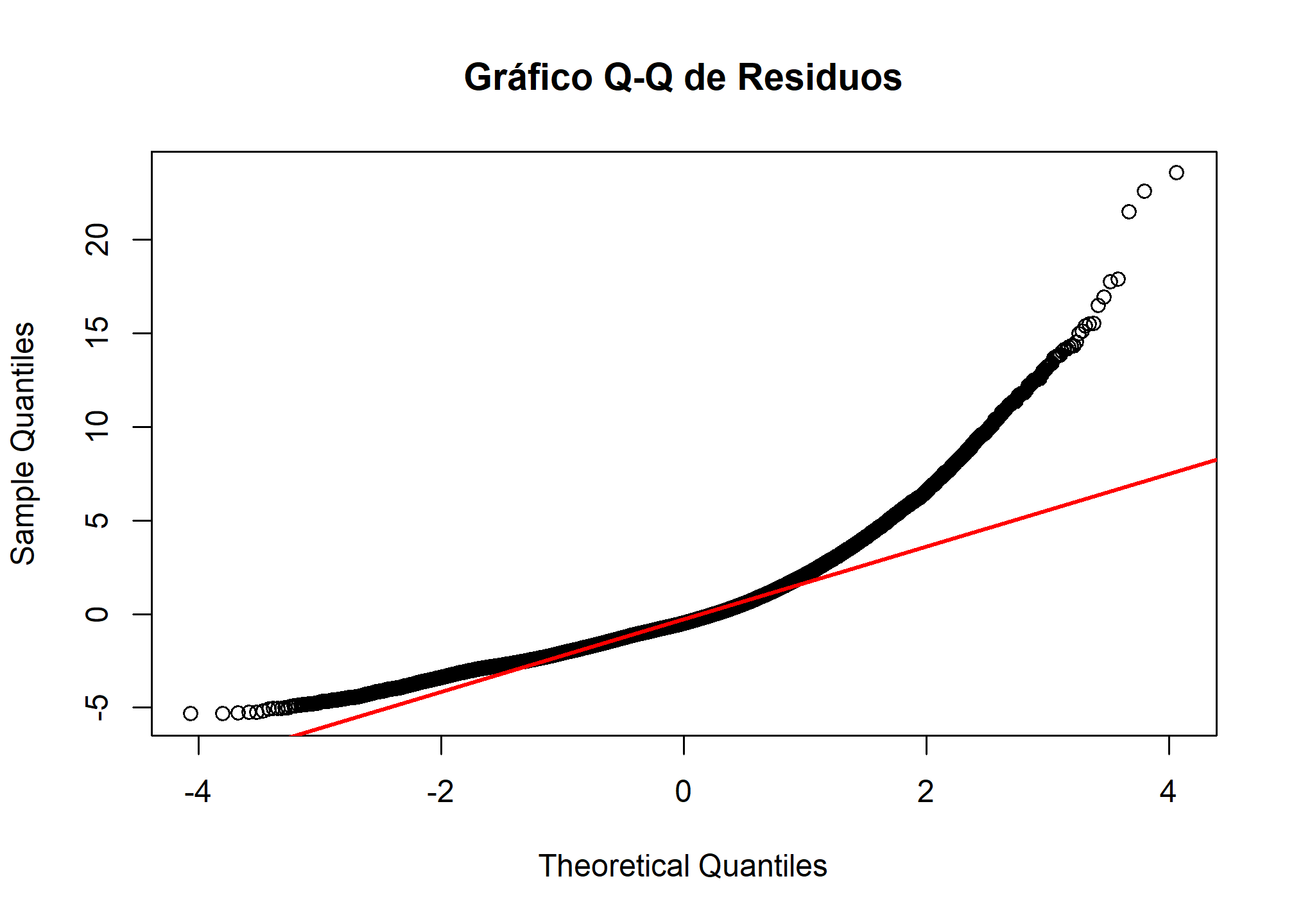
En el gráfico Q-Q, si los residuos están distribuidos normalmente, deberían alinearse aproximadamente sobre la línea roja. Si hay desviaciones sistemáticas de la línea (por ejemplo, si los puntos forman una curva), esto indica que los residuos no siguen una distribución normal, lo cual podría ser problemático para la validez de las inferencias.