3. Regresión Lineal Simple I
0. Objetivo del práctico
El objetivo de este práctico es comprender el cálculo manual de una regresión lineal simple, la obtención de una regresión utilizando la función lm en R, la presentación de los resultados de manera clara con el paquete texreg, y la visualización de la recta de regresión con geom_smooth en ggplot2.
Para esto usaremos datos comunales de registros administrativos y del Censo sobre salarios, educación y ruralidad para analizar las diferencias territoriales de la brecha salarial de género. Los datos de registros administrativos en diversos ámbitos pueden encontrarse en el siguiente enlace https://observatorio.ministeriodesarrollosocial.gob.cl/rraa-2023
Calcularemos la brecha salarial media a partir de la formula vista en la clase anterior:
$$
\frac{\text{Salario Promedio Hombres} - \text{Salario Promedio Mujeres}}{\text{Salario Promedio Hombres}} \times 100
$$
pacman::p_load(dplyr, ggplot2, texreg)
datos <- readRDS(url("https://github.com/GabrielSotomayorl/aadi2024/raw/main/content/example/input/data/datos.rds")) %>%
select(comuna,ing_prom_hombre, ing_prom_mujer,prom_esc = promedio_anios_escolaridad25_2017, prop_rural_2020, ) %>%
mutate(brecha = (ing_prom_hombre - ing_prom_mujer)/ing_prom_hombre*100)
Trabajaremos con las siguientes variables:
- Comuna
- Ingreso promedio de los hombres ocupados formales (RRAA MDSF)
- Ingreso promedio de las mujeres ocupados formales (RRAA MDSF)
- Promedio de años de escolaridad de la población mayor de 25 años hasta el año 2017 (Censo 2017).
- Brecha salarial media comunal (Calculada por nosotros).
Recta de Regresión Lineal simple
La recta de regresión mínimo-cuadrática de \(y\) con relación a \(x\) es la recta que hace que la suma de los cuadrados de las distancias verticales de los puntos observados a la recta sea lo más pequeña posible.
Fórmula General
La recta de regresión se expresa como:
$$ \hat{y} = a + bx $$
- Pendiente
\(b\): Indica el cambio promedio en la variable respuesta\(y\)por cada unidad de cambio en la variable explicativa\(x\). - Ordenada en el origen
\(a\): Representa el valor predicho de\(y\)cuando\(x = 0\). Sólo tiene significado estadístico cuando\(x\)toma valores cercanos a 0.
Cálculo manual de la regresión
Para calcular manualmente la pendiente ($b$) y la ordenada en el origen ($a$) de la recta de regresión, utilizamos las siguientes fórmulas:
$$ b = r \frac{s_y}{s_x} $$
$$ a = \bar{y} - b\bar{x} $$
Donde:
\(r\)es la correlación entre las variables\(x\)e\(y\).\(s_x\)y\(s_y\)son las desviaciones estándar de\(x\)e\(y\).\(\bar{x}\)y\(\bar{y}\)son las medias de\(x\)e\(y\).
Ejemplo con los datos
# Cálculo de la pendiente y ordenada manualmente
r <- cor(datos$brecha, datos$prom_esc)
sx <- sd(datos$prom_esc)
sy <- sd(datos$brecha)
mean_x <- mean(datos$prom_esc)
mean_y <- mean(datos$brecha)
b <- r * (sy / sx)
a <- mean_y - b * mean_x
paste("Pendiente:", round(b, 2), "| Ordenada:", round(a, 2))
## [1] "Pendiente: 2.85 | Ordenada: -16.45"
Cálculo Manual de la Regresión Lineal Simple
A continuación, se explica paso a paso cómo calcular manualmente los parámetros de la recta de regresión lineal simple, es decir, la pendiente ($b$) y el intercepto ($a$). Esto se realiza utilizando la fórmula para la pendiente basada en la correlación y las desviaciones estándar, y la fórmula para la ordenada basada en la media de las variables.
Paso 1: Calcular las medias de las variables
Primero, necesitamos calcular las medias de las dos variables involucradas en la regresión:
\(\bar{x}\): Es la media de la variable independiente (promedio de años de escolaridad).\(\bar{y}\): Es la media de la variable dependiente (brecha salarial).
Estas medias se calculan sumando todos los valores de la variable y dividiendo por el número de observaciones.
$$ \bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}, \quad \bar{y} = \frac{\sum_{i=1}^{n} y_i}{n} $$
Paso 2: Calcular las desviaciones estándar
A continuación, calculamos las desviaciones estándar de ambas variables, que son medidas de dispersión que indican cuánto varían los datos con respecto a sus medias.
\(s_x\): Es la desviación estándar de la variable independiente (promedio de años de escolaridad).\(s_y\): Es la desviación estándar de la variable dependiente (brecha salarial).
La desviación estándar se calcula con la siguiente fórmula:
$$ s_x = \sqrt{\frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1}}, \quad s_y = \sqrt{\frac{\sum_{i=1}^{n} (y_i - \bar{y})^2}{n-1}} $$
Paso 3: Calcular la correlación entre las variables
La correlación ($r$) entre las dos variables mide la fuerza y la dirección de su relación lineal. Se calcula utilizando la siguiente fórmula:
$$ r = \frac{\sum_{i=1}^{n} \left( \frac{x_i - \bar{x}}{s_x} \right) \left( \frac{y_i - \bar{y}}{s_y} \right)}{n-1} $$
Paso 4: Calcular la pendiente ($b$)
Con la correlación y las desviaciones estándar calculadas, podemos encontrar la pendiente ($b$) de la recta de regresión. La pendiente indica el cambio esperado en la variable dependiente por cada unidad de cambio en la variable independiente.
$$ b = r \frac{s_y}{s_x} $$
Paso 5: Calcular la ordenada en el origen ($a$)
Finalmente, calculamos la ordenada en el origen ($a$), que es el valor de la variable dependiente cuando la variable independiente es cero. Esto se calcula usando la pendiente y las medias de las variables.
$$ a = \bar{y} - b\bar{x} $$
Resumen de los resultados
Al seguir estos pasos, se obtienen los valores de \(b\) (pendiente) y \(a\) (ordenada en el origen), que definen la recta de regresión lineal simple:
$$ \hat{y} = a + bx $$
Este proceso manual nos ayuda a entender cómo se deriva la ecuación de regresión a partir de las características estadísticas de las variables, proporcionándonos una comprensión más profunda de los fundamentos detrás del análisis de regresión.
Regresión con la función lm
La función lm (por linear model) en R se utiliza para ajustar modelos de regresión lineal. La sintaxis básica es:
lm(y ~ x, data = datos)
- y corresponde a la variable dependiente.
- x corresponde a la variable independiente y
- El argumento data corresponde a la base de datos a utilizar.
Aplicamos esto a nuestro conjunto de datos para obtener la recta de regresión de la brecha salarial en función de los años de escolaridad promedio de la comuna.
lm(brecha ~ prom_esc, data = datos)
##
## Call:
## lm(formula = brecha ~ prom_esc, data = datos)
##
## Coefficients:
## (Intercept) prom_esc
## -16.451 2.852
Para obtener un reporte más detallado de los resultados guardamos los resultados de nuestro modelo como un objeto y le aplicamos la función summary()
modelo <- lm(brecha ~ prom_esc, data = datos)
summary(modelo)
##
## Call:
## lm(formula = brecha ~ prom_esc, data = datos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.988 -5.769 -1.492 5.403 25.817
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -16.4513 3.1790 -5.175 4.02e-07 ***
## prom_esc 2.8520 0.3216 8.868 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8.513 on 321 degrees of freedom
## Multiple R-squared: 0.1968, Adjusted R-squared: 0.1943
## F-statistic: 78.64 on 1 and 321 DF, p-value: < 2.2e-16
Interpretación de los coeficientes:
-
Intercepto: El valor del intercepto es -16.4513. Esto significa que, si el promedio de años de escolaridad fuera 0 (aunque no sea un escenario realista), la brecha salarial de género sería de -16.45%, lo que implica que, en ausencia de escolaridad, se esperaría que las mujeres ganaran un 16.45% más que los hombres en promedio. Sin embargo, este valor tiene poco sentido práctico, dado que la escolaridad no puede ser cero en la realidad.
-
Beta de regresión: La pendiente de la regresión (2.8520) indica que por cada año adicional de escolaridad promedio en una comuna, la brecha salarial de género promedio (o predicha por el modelo) se incrementa en un 2.85%. Esto sugiere una relación positiva entre los años de escolaridad y la brecha salarial, donde más años de educación promedio se asocian con una mayor brecha salarial en favor de los hombres.
-
R-cuadrado: El
\(R^2\)de 0.1968 indica que aproximadamente el 19.68% de la variabilidad en la brecha salarial puede explicarse por el modelo lineal simple que incluye el promedio de años de escolaridad como predictor. Aunque este valor no es muy alto, sugiere que existen otros factores importantes que también afectan la brecha salarial de género y que no están capturados por este modelo simple.
Presentación de resultados con texreg
El paquete texreg permite presentar los resultados de modelos de regresión de una manera clara.
# Instalar y cargar el paquete texreg si no está ya instalado
# install.packages("texreg")
library(texreg)
# Presentar el modelo
screenreg(modelo, custom.coef.names = c("Intercepto", "Promedio de años de escolaridad")) #Para visualizar en la consola
##
## ===========================================
## Model 1
## -------------------------------------------
## Intercepto -16.45 ***
## (3.18)
## Promedio de años de escolaridad 2.85 ***
## (0.32)
## -------------------------------------------
## R^2 0.20
## Adj. R^2 0.19
## Num. obs. 323
## ===========================================
## *** p < 0.001; ** p < 0.01; * p < 0.05
htmlreg(modelo,
#file = "tabla_regresion.html", #Linea para exportar el archivo
custom.coef.names = c("Intercepto", "Promedio de años de escolaridad"))
| Model 1 | |
|---|---|
| Intercepto | -16.45*** |
| (3.18) | |
| Promedio de años de escolaridad | 2.85*** |
| (0.32) | |
| R2 | 0.20 |
| Adj. R2 | 0.19 |
| Num. obs. | 323 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Visualización de la recta de regresión
ggplot2 ofrece la función geom_smooth para agregar líneas de regresión a gráficos de dispersión. Usaremos esta función para visualizar la relación entre la brecha salarial de género y los años de escolaridad.
1. ggplot(datos, aes(x = prom_esc, y = brecha))
ggplot(datos, aes(x = prom_esc, y = brecha)):
Esta línea inicializa un gráfico utilizandoggplot2, especificando la base de datosdatosy estableciendo el sistema de coordenadas. Dentro deaes, se define la estética (o mapeo estético) del gráfico:x = prom_esc: Establece que la variableprom_esc(promedio de años de escolaridad en la comuna) se ubicará en el eje X.y = brecha: Establece que la variablebrecha(brecha salarial de género) se ubicará en el eje Y.
2. geom_point(color = "#0073C2", size = 3, alpha = 0.7)
geom_point:
Añade una capa de puntos al gráfico para visualizar la relación entre las dos variables (gráfico de dispersión).color = "#0073C2": Define el color de los puntos (en este caso, un azul específico).size = 3: Establece el tamaño de los puntos en el gráfico.alpha = 0.7: Controla la transparencia de los puntos (0 es completamente transparente, 1 es completamente opaco). Aquí, los puntos son ligeramente transparentes para mejorar la visualización en caso de solapamiento.
3. geom_smooth(method = "lm", color = "black", linetype = "solid", se = FALSE)
geom_smooth:
Esta función añade una línea de suavizado (o tendencia) al gráfico. En este caso, se utiliza para agregar una línea de regresión lineal que resuma la relación entre las variablesx(prom_esc) ey(brecha).method = "lm": Indica que la línea de suavizado debe basarse en un modelo de regresión lineal (lm, de “linear model”). Esto es crucial para asegurar que la línea añadida sea una recta que minimice los residuos, de acuerdo con el modelo de regresión lineal simple.color = "black": Define que la línea de regresión será negra.linetype = "solid": Especifica que la línea será sólida (sin guiones o puntos).se = FALSE: Especifica que no se debe mostrar la banda de error estándar alrededor de la línea de regresión. Esta banda indicaría el intervalo de confianza de la estimación de la línea de regresión, pero en este caso se omite para mantener el gráfico más limpio.
ggplot(datos, aes(x = prom_esc, y = brecha)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7) + # Puntos más grandes y ligeramente transparentes
geom_smooth(method = "lm", color = "black", linetype = "solid", se = FALSE) + # Línea de tendencia en negro
labs(
x = "Promedio de Años de Escolaridad (2017)",
y = "Brecha Salarial de Género (%)",
title = "Relación entre Promedio de Años de Escolaridad y Brecha Salarial de Género"
) +
theme_minimal(base_size = 16) + # Tamaño base de letra aumentado
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 18), # Título centrado, en negrita y más grande
axis.title = element_text(face = "bold", size = 14), # Títulos de los ejes en negrita y más grandes
axis.text = element_text(color = "#333333", size = 12), # Texto de los ejes más grande
panel.grid.major = element_line(color = "#e0e0e0"), # Líneas de la cuadrícula mayor en gris claro
panel.grid.minor = element_blank() # Elimina las líneas de la cuadrícula menor
)
## `geom_smooth()` using formula = 'y ~ x'
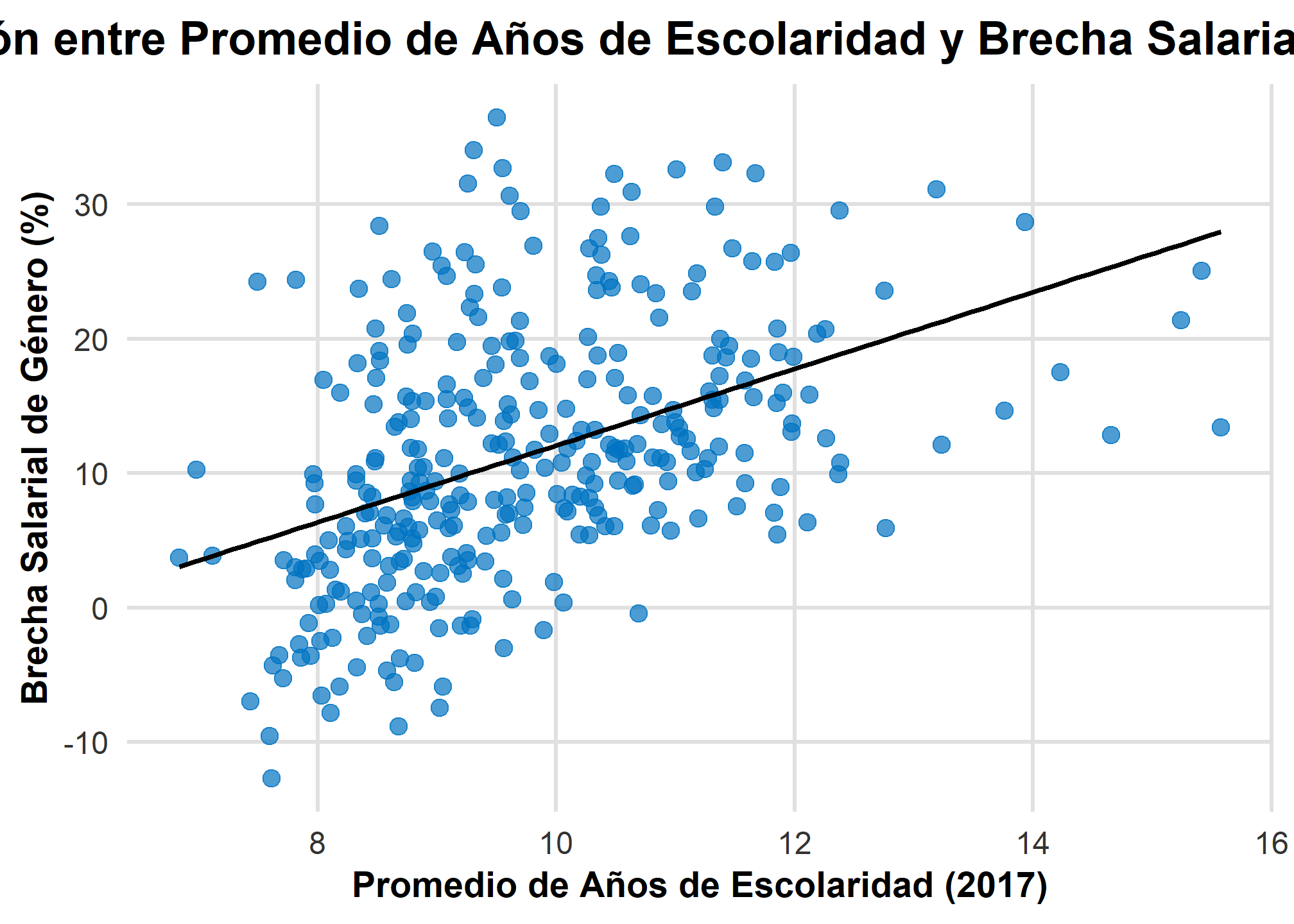
Gráfico interactivo de correlación y regresión
A continuación se presenta una herramienta que podrán usar para visualizar de mejor manera como se calcula una correlación o se ajusta una recta de regresión a partir de una nube de puntos.
Para acceder de mejor manera a la aplicación pueden acceder a este enlace: https://gabriel-sotomayor.shinyapps.io/rls_aad/.