2. Visualización de datos y correlación
0. Objetivo del práctico
El objetivo de este práctico es introducir el uso de ggplot para la construcción de visualizaciones de datos en el contexto de análisis bivariado, así como la obtención de estadísiticos descriptivos y de correlación con R.
Para esto usaremos datos comunales de registros administrativos y del Censo sobre salarios, educación y ruralidad para analizar las diferencias territoriales de la brecha salarial de género. Los datos de registros administrativos en diversos ámbitos pueden encontrarse en el siguiente enlace https://observatorio.ministeriodesarrollosocial.gob.cl/rraa-2023
pacman::p_load(dplyr, ggplot2)
datos <- readRDS(url("https://github.com/GabrielSotomayorl/aadi2024/raw/main/content/example/input/data/datos.rds")) %>%
select(comuna,ing_prom_hombre, ing_prom_mujer,prom_esc = promedio_anios_escolaridad25_2017, prop_rural_2020, )
Trabajaremos con las siguientes variables:
- Comuna
- Ingreso promedio de los hombres ocupados formales (RRAA MDSF)
- Ingreso promedio de las mujeres ocupados formales (RRAA MDSF)
- Promedio de años de escolaridad de la población mayor de 25 años hasta el año 2017 (Censo 2017).
- Porcentaje de población rural por comuna (Proyecciones de población INE).
Cálculo de la brecha salarial
Utilizaremos la brecha salarial media de cada comuna como la variable de interés en nuestro análisis. Esta variable es crucial para entender las disparidades de ingresos entre hombres y mujeres a nivel comunal. La brecha salarial media se calcula utilizando la siguiente fórmula:
$$
\frac{\text{Salario Promedio Hombres} - \text{Salario Promedio Mujeres}}{\text{Salario Promedio Hombres}} \times 100
$$
Este cálculo nos da un porcentaje que representa cuánto menos ganan, en promedio, las mujeres en comparación con los hombres en una comuna específica. Un valor positivo indica que, en promedio, los hombres ganan más que las mujeres, mientras que un valor negativo indicaría lo contrario (aunque en la práctica, lo común es encontrar valores positivos).
Por ejemplo si en una comuna el salario promedio de los hombres es de $400.000 y el de las mujeres es 300.000
$$
\text{Brecha Salarial de Género} = \frac{100.000}{400.000} \times 100 = 0.25 \times 100 = 25%
$$
Esto significa que, en esta comuna, las mujeres ganan en promedio un 25% menos que los hombres.
Ahora calcularemos esta variable para cada una de las comunas en nuestra base de datos integrando la fórmula en el cálculo de una nueva variable con mutate.
datos <- datos %>%
mutate(brecha = (ing_prom_hombre - ing_prom_mujer)/ing_prom_hombre*100)
Exploración de datos y presentación de tablas
Para obtener una visión general completa de los datos, podemos utilizar la función dfSummary del paquete summarytools. Esta función genera un resumen detallado de cada variable en la base de datos, con estad´siticos descritpivos y una visualición simple.
# Instalar y cargar summarytools si no está ya instalado
#install.packages("summarytools")
library(summarytools)
## Warning: package 'summarytools' was built under R version 4.3.1
# Crear el resumen de los datos y renderizarlo en HTML
resumen <- dfSummary(datos)
print(resumen, headings = FALSE)
##
## -------------------------------------------------------------------------------------------------------------------------
## No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ----------------- --------------------------------- --------------------- --------------------- ---------- ---------
## 1 comuna 1. aisen 1 ( 0.3%) 323 0
## [character] 2. algarrobo 1 ( 0.3%) (100.0%) (0.0%)
## 3. alhue 1 ( 0.3%)
## 4. alto biobio 1 ( 0.3%)
## 5. alto del carmen 1 ( 0.3%)
## 6. alto hospicio 1 ( 0.3%)
## 7. ancud 1 ( 0.3%)
## 8. andacollo 1 ( 0.3%)
## 9. angol 1 ( 0.3%)
## 10. antofagasta 1 ( 0.3%)
## [ 313 others ] 313 (96.9%) IIIIIIIIIIIIIIIIIII
##
## 2 ing_prom_hombre Mean (sd) : 846242.9 (245294.3) 323 distinct values . : 323 0
## [numeric] min < med < max: : : (100.0%) (0.0%)
## 542650.4 < 788682.4 < 2545608 : :
## IQR (CV) : 235971.3 (0.3) : : :
## : : : .
##
## 3 ing_prom_mujer Mean (sd) : 736903.5 (171422.1) 323 distinct values : 323 0
## [numeric] min < med < max: : (100.0%) (0.0%)
## 450713.6 < 698073.2 < 1907486 :
## IQR (CV) : 142665.7 (0.2) : .
## : : :
##
## 4 prom_esc Mean (sd) : 9.8 (1.5) 323 distinct values : 323 0
## [numeric] min < med < max: . : . (100.0%) (0.0%)
## 6.8 < 9.5 < 15.6 : : : :
## IQR (CV) : 2 (0.2) : : : : :
## . : : : : : .
##
## 5 prop_rural_2020 Mean (sd) : 32.3 (26) 285 distinct values : 323 0
## [numeric] min < med < max: : (100.0%) (0.0%)
## 0 < 29.1 < 100 : . . .
## IQR (CV) : 41.4 (0.8) : : : : : : .
## : : : : : : : . :
##
## 6 brecha Mean (sd) : 11.4 (9.5) 323 distinct values : 323 0
## [numeric] min < med < max: : : . (100.0%) (0.0%)
## -12.7 < 10.8 < 36.5 : : : .
## IQR (CV) : 12.1 (0.8) : : : : : :
## . : : : : : : : : .
## -------------------------------------------------------------------------------------------------------------------------
#Esta linea permite obtener una versión html del resumen en el navegador
#print(resumen, headings = FALSE, method = "browser")
Para presentar estadísticas descriptivas de las variables numéricas de manera clara y mejorada visualmente, puedes utilizar kable junto con kableExtra.
kable: Es una función del paquete knitr que permite crear tablas básicas en formatos como HTML, LaTeX, y Markdown. Es ideal para convertir data frames y matrices en tablas legibles y presentables en documentos.
kableExtra: Es un paquete adicional que extiende las capacidades de kable. Proporciona herramientas avanzadas para estilizar tablas, añadiendo opciones de diseño como colores, bordes, líneas, y otras características visuales que mejoran significativamente la apariencia de las tablas en informes y presentaciones.
# Instalar y cargar knitr y kableExtra si no están ya instalados
# install.packages("knitr")
# install.packages("kableExtra")
library(knitr)
## Warning: package 'knitr' was built under R version 4.3.3
library(kableExtra)
## Warning: package 'kableExtra' was built under R version 4.3.1
# Calcular estadísticas descriptivas
descriptivas <- datos %>%
summarise(
Minimo = min(brecha, na.rm = TRUE),
Q1 = quantile(brecha, 0.25, na.rm = TRUE),
Media = mean(brecha, na.rm = TRUE),
Mediana = median(brecha, na.rm = TRUE),
Q3 = quantile(brecha, 0.75, na.rm = TRUE),
Maximo = max(brecha, na.rm = TRUE),
DesviacionEstandar = sd(brecha, na.rm = TRUE)
)
# Mostrar la tabla con kable y kableExtra
descriptivas %>%
kable("html", caption = "Estadísticas Descriptivas de la Brecha Salarial") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))
| Minimo | Q1 | Media | Mediana | Q3 | Maximo | DesviacionEstandar |
|---|---|---|---|---|---|---|
| -12.71823 | 5.314829 | 11.42497 | 10.84059 | 17.36508 | 36.46484 | 9.483745 |
Ahora podemos ver como se agrupan las comunas en distintos niveles de brecha salarial. Para crear una tabla de frecuencias basada en la variable brecha, primero necesitamos recodificar la variable de manera categórica.
datos <- datos %>%
mutate(brecha_recodificada = cut(brecha, breaks = c(-12.8, 0, 12, 24, 36.5),
labels = c("-13% - 0%", "0% - 12%", "12% - 24%", "24% - 36.5%")))
# Generar tabla de frecuencias
frecuencias <- datos %>%
group_by(brecha_recodificada) %>%
summarise(Frecuencia = n()) %>%
mutate(Porcentaje = round((Frecuencia / sum(Frecuencia)) * 100, 2))
# Mostrar la tabla con kable y kableExtra
frecuencias %>%
kable("html", caption = "Tabla de Frecuencias de la Brecha Salarial Recodificada") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))
| brecha_recodificada | Frecuencia | Porcentaje |
|---|---|---|
| -13% - 0% | 35 | 10.84 |
| 0% - 12% | 147 | 45.51 |
| 12% - 24% | 102 | 31.58 |
| 24% - 36.5% | 39 | 12.07 |
Construcción de gráficos con ggplot2
La principal herramienta de visualización de datos en R es el paquete ggplot2, que forma parte de tidyverse. ggplot2 implementa la gramática de los gráficos, un sistema coherente para describir y construir gráficos.
Su versatilidad y capacidad de obtener resultados visualmente atractivos lo hacen más pertinente para tareas de presentación de resultados, tanto a públicos especializados como no especializados.
Veremos los elementos básicos para poder hacer uso del paquete más adelante en el contexto de las técnicas estadísticas a ver en el curso.
| Capa | Descripción |
|---|---|
| Datos | Conjunto de información que se representará de manera gráfica. En nuestro caso se trata de una o más variables, o una base de datos. |
| Estética | Escala en la cual se posicionará la información de interés. Refiere al posicionamiento de la información a representar sobre los diferentes ejes y dimensiones del gráfico resultante. Hablamos del posicionamiento de variables en los ejes X e Y como también de la posibilidad de indicar variables que pueden ser posicionadas como color de relleno dentro de los diferentes ejes, como una función de transparencia, etc. |
| Geometría | Formas, elementos visuales, que se emplearán para representar visualmente la información ya consignada en los datos y ubicada en las diferentes posiciones del gráfico mencionadas en la estética. Cada especificación de geometría permite visualizar diferentes características de la(s) variable(s) y su distribución. |
En primer lugar tenemos que seleccionar un conjunto de datos sobre el que trabajaremos. Podemos hacer esto de manera integrada con el flujo de trabajo del pipeline que vimos para dplyr.
#install.packages("ggplot2")
library(ggplot2)
datos %>%
ggplot()

El resultado de entregar solo una base de datos a ggplot será un gráfico vaciO, sin información en sus ejes, ni representaciones gráficas de los datos. El siguiente paso es definir la estética o aesthetics, mediante la función aes(), en la cual indicaremos cuales son las variables que constituirán los ejes de nuestro gráfico. En este caso construiremos un gráfico con una sola variable, por lo que pondremos la edad en el eje x.
Cada capa adicional que vayamos agregando a nuestro gráfico en ggplot 2 debe agregarse mediante un “+”. No confundir con el trabajo con el pipeline.
datos %>%
ggplot() +
aes(x = brecha)
Por último, necesitamos decirle a ggplot como representar nuestros datos en el eje señalado mediante un geom, es decir, el objeto geométrico que se utilizará para representar los datos. Para esto hay múltiple funciones que empiezan con “geom_”, como geom_bar, geom_point o geom_line. En este caso queremos contruir un histograma así que usaremos geom_histogram.
datos %>%
ggplot() +
aes(x = brecha) +
geom_histogram()
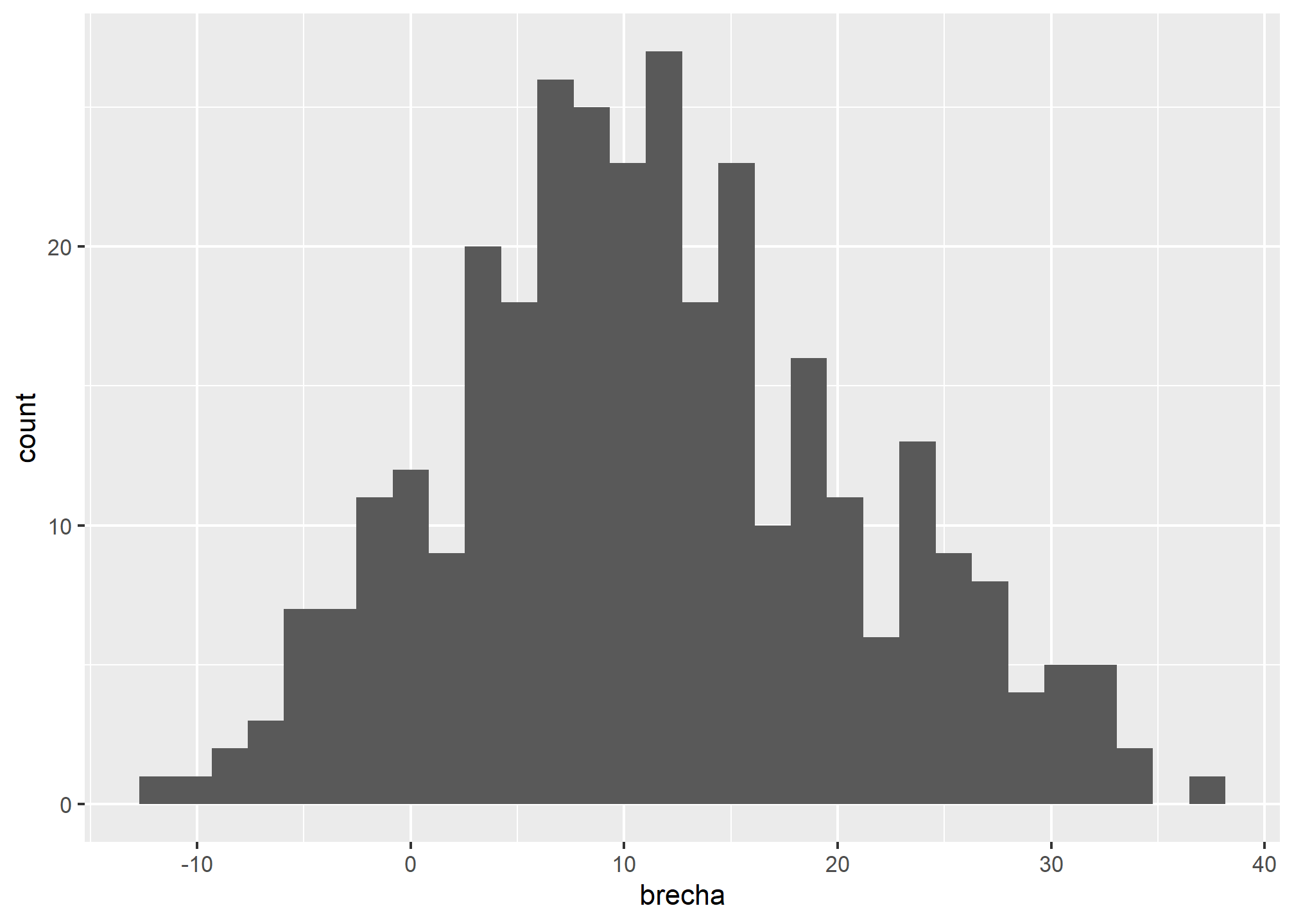
Ya tenemos una visualización básica. Ahora introduciremos algunos elementos adicionales para mejorar la apariencia de nuestro gráfico.
- labs(): Se añaden un título, un subtítulo y una nota al pie (caption) para proporcionar contexto y citar la fuente de los datos. Esto mejora la comprensión del gráfico por parte del espectador.
theme_minimal(): Se aplica un tema minimalista al gráfico para un aspecto limpio y moderno.
-
labs(): Se añaden un título, un subtítulo y una nota al pie (caption) para proporcionar contexto y citar la fuente de los datos. Esto mejora la comprensión del gráfico por parte del espectador.
-
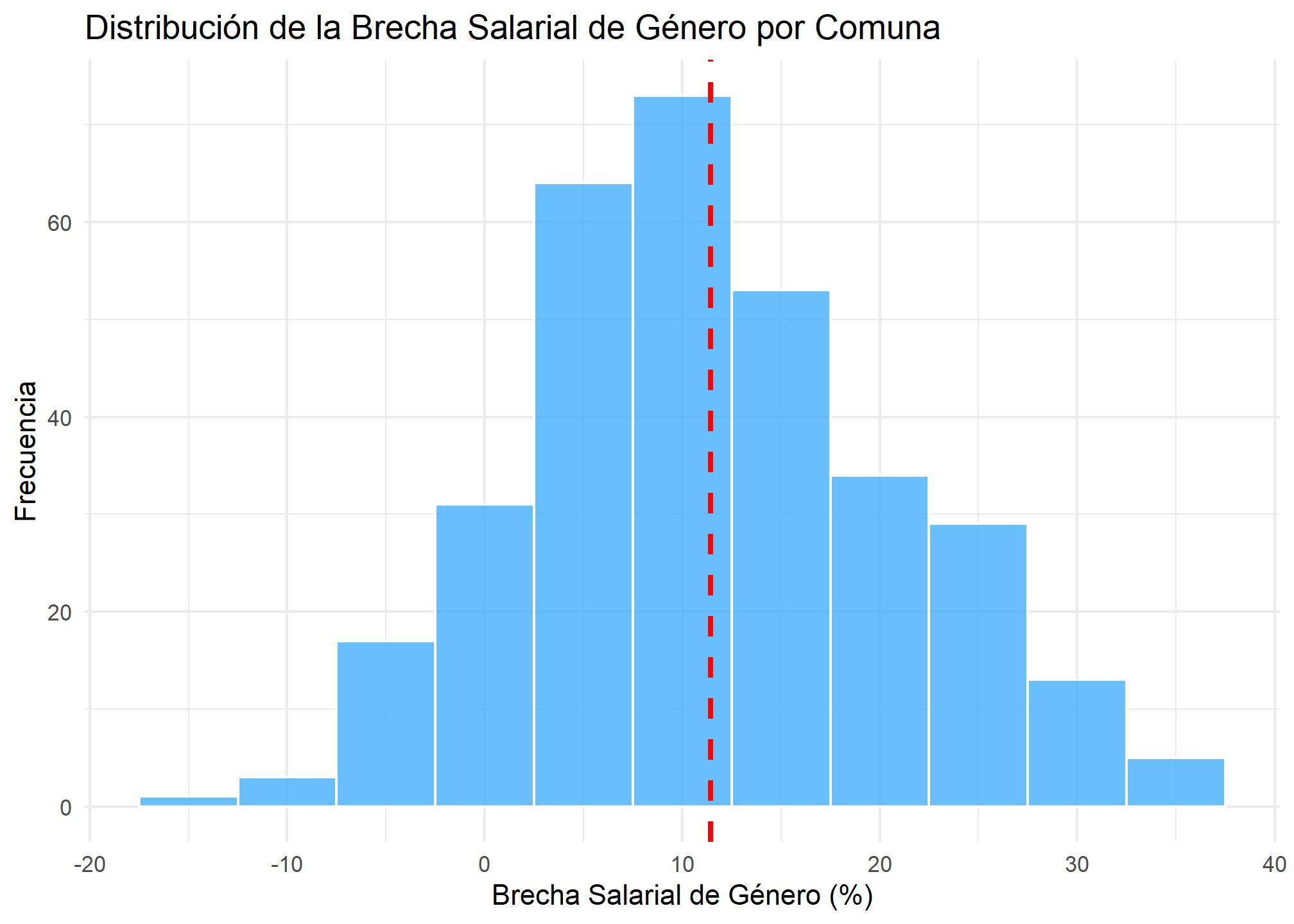
Al final utilizamos geom_vline para añadir una linea roja punteada que indique la media de la variable. Ojo que esta tiene su propio aes que no corresponde al del resto del gráfico.
ggplot(datos, aes(x = brecha)) +
geom_histogram(
binwidth = 5, # Ajusta el ancho de las barras
fill = "#42affa", # Color de relleno de las barras
color = "white", # Color de borde de las barras
alpha = 0.8 # Transparencia de las barras
) +
labs(
x = "Brecha Salarial de Género (%)",
y = "Frecuencia",
title = "Distribución de la Brecha Salarial de Género por Comuna"
) +
theme_minimal() +
geom_vline(
aes(xintercept = mean(datos$brecha)),
color = "red", # Color de la línea
linetype = "dashed", # Tipo de línea (discontinua)
size = 1 # Grosor de la línea
)
Ahora veamos el ejemplo de un gráfico bivariado. para esto debemos fijar una varaible en cada eje para las aesthetics. En este caso veremos la relación entre la brecha salarial de género y el los años de escolaridad promedio de una comuna. Para esto usaremos un gráfiuco de dispersión, construido a partir de geom_point().
datos %>%
ggplot( aes(x = prom_esc, y =brecha)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7)
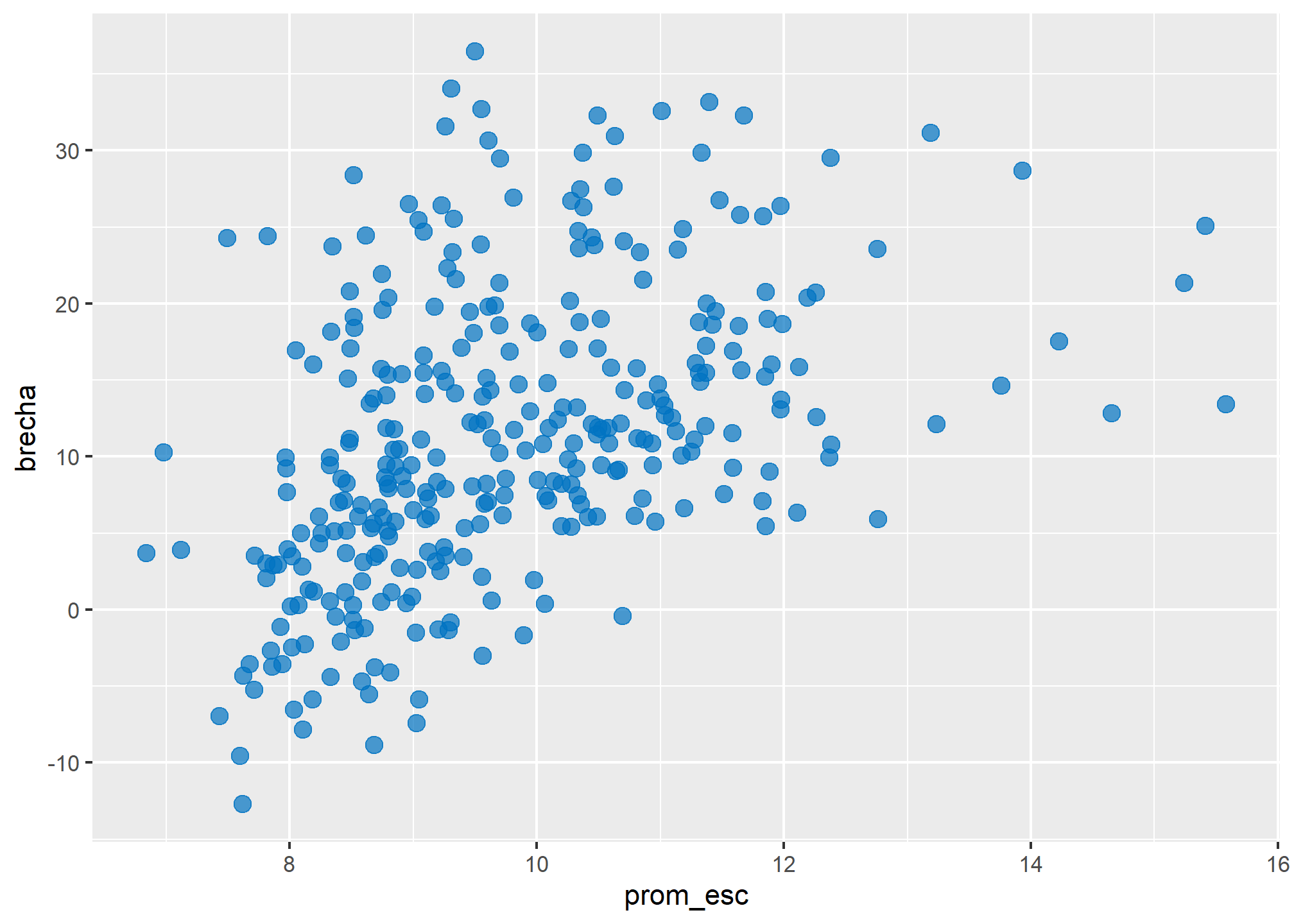
Como vemos el gráfico tiene los años de escolaridad promedio en el eje x, y la brecha salarial de género media en el eje y.
ggplot(datos, aes(x = prom_esc, y =brecha)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7) + # Puntos más grandes y ligeramente transparentes
# geom_smooth(method = "lm", color = "red", linetype = "dashed", se = FALSE) + # Línea de tendencia con estilo
labs(
x = "Promedio de Años de Escolaridad (2017)",
y = "Brecha Salarial de Género (%)",
title = "Relación entre Brecha Salarial de Género y Promedio de Años de Escolaridad"
) +
theme_minimal() # Tamaño base de letra aumentado
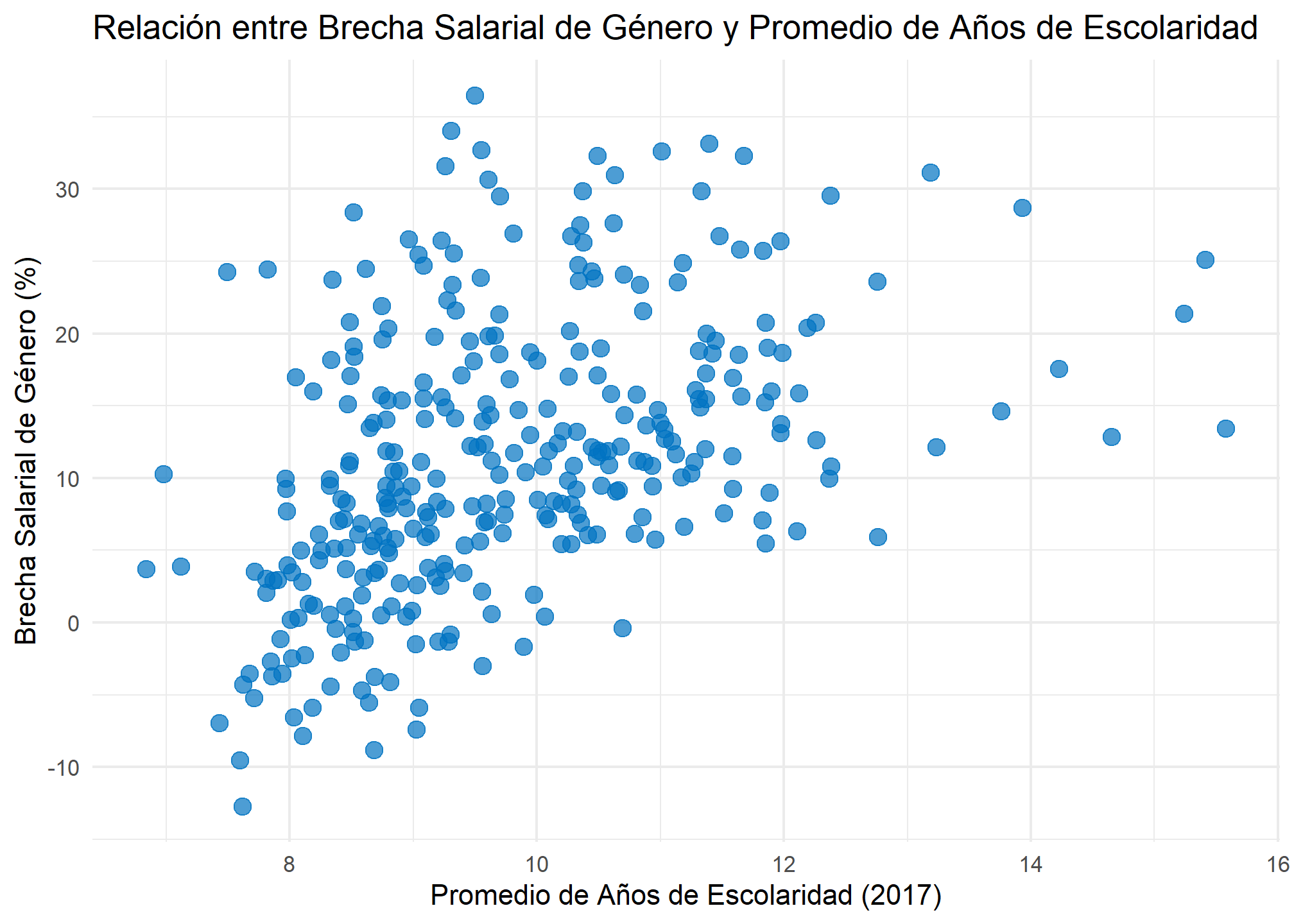
Por último agregamos las etiquetas del gráfico y otros elementos estéticos para mejorar su presentación.
Estadística descriptiva y bivariada
Varianza
La varianza mide la dispersión de los datos respecto a la media. Se calcula usando la siguiente fórmula:
$$ Var(X) = \frac{1}{n-1} \sum_{i=1}^{n} (X_i - \bar{X})^2 $$
Donde:
- ( X_i ) son los valores de la variable,
- ( \bar{X} ) es la media de ( X ),
- ( n ) es el número de observaciones.
Vamos a calcular la varianza de la variable brecha:
# Media de la variable
media_brecha <- mean(datos$brecha, na.rm = TRUE)
# Cálculo de la varianza manualmente
varianza_manual <- sum((datos$brecha - media_brecha)^2, na.rm = TRUE) / (length(datos$brecha) - 1)
varianza_manual
## [1] 89.94141
var(datos$brecha, na.rm = TRUE)
## [1] 89.94141
Correlación
La correlación de Pearson entre dos variables𝑋y𝑌se calcula de la siguiente manera: $$ r = \frac{1}{n-1} \sum \left( \frac{x_i - \bar{x}}{s_x} \right) \left( \frac{y_i - \bar{y}}{s_y} \right) $$ Vamos a calcular manualmente la correlación entre la variable brecha y promedio de escolaridad:
# Media de las variables
media_brecha <- mean(datos$brecha, na.rm = TRUE)
media_esc <- mean(datos$prom_esc, na.rm = TRUE)
# Desviación estándar de las variables
sd_brecha <- sd(datos$brecha, na.rm = TRUE)
sd_esc <- sd(datos$prom_esc, na.rm = TRUE)
# Cálculo de las desviaciones estandarizadas y del producto de las desviaciones estandarizadas
producto_estandarizado <- (datos$brecha - media_brecha) / sd_brecha * (datos$prom_esc - media_esc) / sd_esc
# Suma de los productos de las desviaciones estandarizadas
suma_productos <- sum(producto_estandarizado, na.rm = TRUE)
# Número de observaciones
n <- sum(!is.na(datos$brecha) & !is.na(datos$prom_esc))
# Cálculo de la correlación manualmente
correlacion_manual <- suma_productos / (n - 1)
# Mostrar el resultado de la correlación manual
correlacion_manual
## [1] 0.4435958
cor(datos$brecha, datos$prom_esc)
## [1] 0.4435958
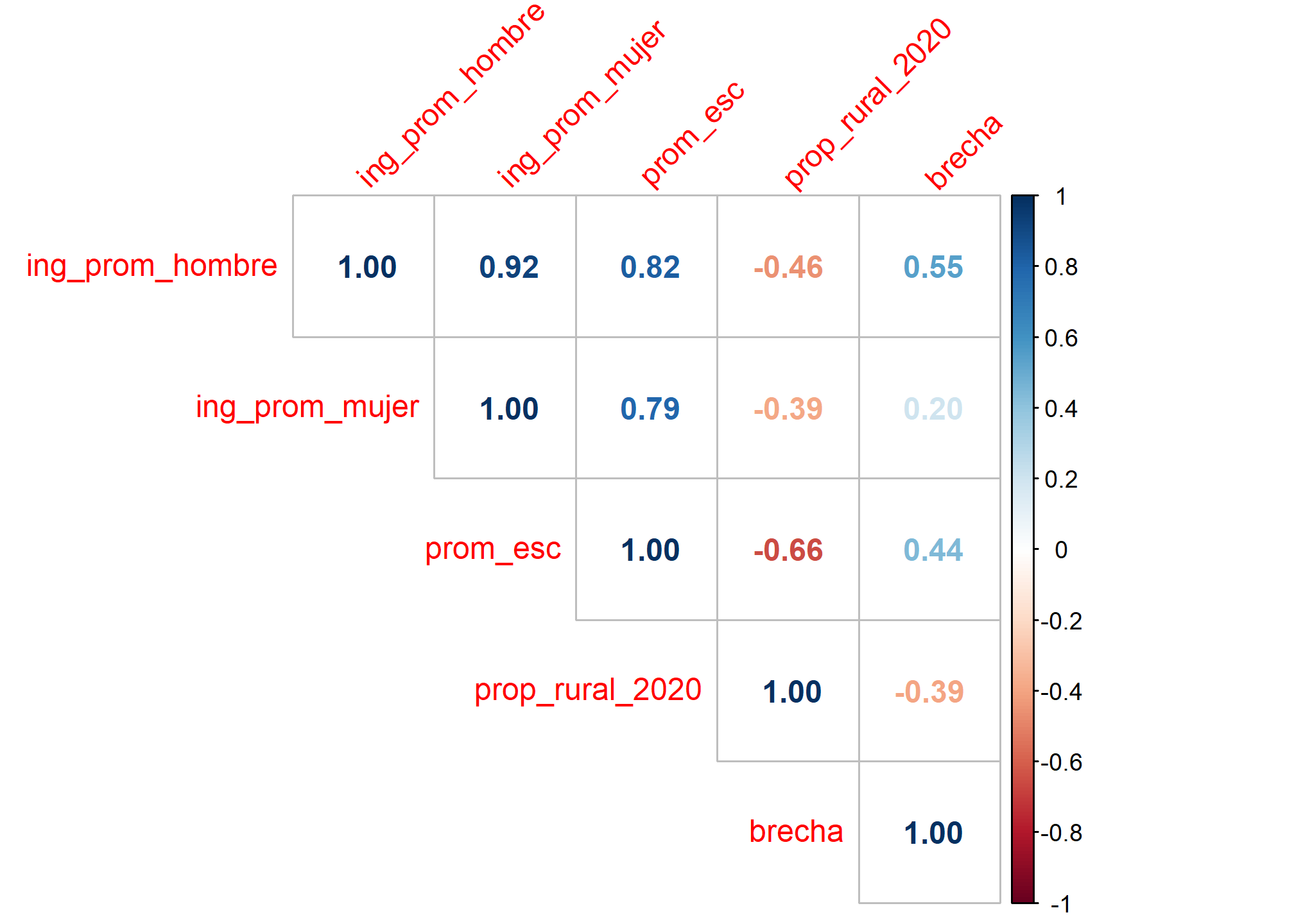
Para analizar la relación entre todas las variables numéricas de la base de datos (exceptuando la variable comuna), podemos construir una matriz de correlaciones:
matriz_correlacion <- cor(datos[,-c(1,7)], use = "complete.obs")
matriz_correlacion
## ing_prom_hombre ing_prom_mujer prom_esc prop_rural_2020
## ing_prom_hombre 1.0000000 0.9241862 0.8222935 -0.4591061
## ing_prom_mujer 0.9241862 1.0000000 0.7932260 -0.3875617
## prom_esc 0.8222935 0.7932260 1.0000000 -0.6568491
## prop_rural_2020 -0.4591061 -0.3875617 -0.6568491 1.0000000
## brecha 0.5457428 0.2005850 0.4435958 -0.3914522
## brecha
## ing_prom_hombre 0.5457428
## ing_prom_mujer 0.2005850
## prom_esc 0.4435958
## prop_rural_2020 -0.3914522
## brecha 1.0000000
Por último, podemos usar el paquete corrplot para obtener una visualiación rápida de las correlaciones en un conjunto de variables.
# Instalar y cargar el paquete necesario
# install.packages("corrplot")
library(corrplot)
## Warning: package 'corrplot' was built under R version 4.3.1
# Crear el correlograma
corrplot(matriz_correlacion, method = "number", tl.srt = 45, type = "upper")