Análisis de conglomerados jerárquicos
0. Objetivo del Práctico
El objetivo de este práctico es realizar un análisis de conglomerados jerárquico sobre una serie de indicadores socioeconómicos de países de América Latina, utilizando datos del Banco Mundial. Aprenderemos a estandarizar variables, calcular una matriz de distancia, aplicar el método de conglomerados jerárquicos, determinar el número óptimo de grupos, y realizar una caracterización e interpretación de estos grupos. Al final del ejercicio, los estudiantes deberían comprender cómo estas técnicas permiten explorar y descubrir estructuras subyacentes en los datos, sin necesidad de una hipótesis a priori.
1. Carga y Preparación de los Datos
En este primer paso, vamos a cargar los datos y limpiarlos. Utilizaremos la base de datos World Development Indicators (WDI) del Banco Mundial, que contiene datos sobre varios indicadores socioeconómicos a nivel mundial.
if (!requireNamespace("pacman", quietly = TRUE)) install.packages("pacman")
pacman::p_load(dplyr, cluster, factoextra, WDI, knitr, kableExtra)
# Descargar datos relevantes del Banco Mundial para el año 2020
indicadores <- WDI(country = "all",
indicator = c("NY.GDP.PCAP.CD", # PIB per cápita (ingreso)
"SE.XPD.TOTL.GD.ZS", # Gasto en educación (% del PIB)
"SP.DYN.LE00.IN", # Esperanza de vida al nacer (salud)
"SE.SEC.ENRR" # Tasa de matrícula en la educación secundaria (educación)
),
start = 2020, end = 2020, extra = TRUE)
# Limpiar los datos: eliminar regiones y observaciones con valores faltantes
indicadores_clean <- indicadores %>%
filter(!region %in% c("Aggregates", NA)) %>%
filter(region %in% c("Latin America & Caribbean")) %>%
select(country, NY.GDP.PCAP.CD, SE.XPD.TOTL.GD.ZS, SP.DYN.LE00.IN, SE.SEC.ENRR) %>%
na.omit()
# Renombrar columnas para facilitar el trabajo
colnames(indicadores_clean) <- c("country", "gdp_per_capita", "education_exp", "life_expectancy", "secondary_enrollment")
# Ver algunos registros de la base de datos
head(indicadores_clean)
## country gdp_per_capita education_exp life_expectancy
## 2 Argentina 8535.599 5.27690 75.878
## 5 Barbados 19194.492 3.86530 76.647
## 6 Belize 5238.541 5.21302 71.580
## 7 Bolivia 3580.968 8.43711 62.906
## 8 Brazil 7074.194 5.77149 74.506
## 10 Cayman Islands 82338.798 1.45542 79.230
## secondary_enrollment
## 2 112.37673
## 5 104.31899
## 6 86.18866
## 7 88.86724
## 8 103.88266
## 10 84.09091
Hemos descargado datos socioeconómicos que incluyen el PIB per cápita, el gasto en educación, la esperanza de vida y la tasa de matrícula en educación secundaria para los países de América Latina en el año 2020. Luego limpiamos el dataset eliminando observaciones con valores faltantes.
2. Análisis de Correlación entre Variables
Antes de proceder al análisis de conglomerados, es importante entender las relaciones entre nuestras variables mediante un análisis de correlación. Esto nos permite identificar si algunas variables están altamente correlacionadas.
library(corrplot)
## corrplot 0.95 loaded
# Calcular la matriz de correlación
corr_matrix <- cor(indicadores_clean %>% select(-country))
# Visualizar la matriz de correlación con números y colores
corrplot(corr_matrix, method = "color", type = "upper", tl.col = "black", tl.cex = 0.8, title = "Matriz de Correlación", addCoef.col = "black", number.cex = 0.7)
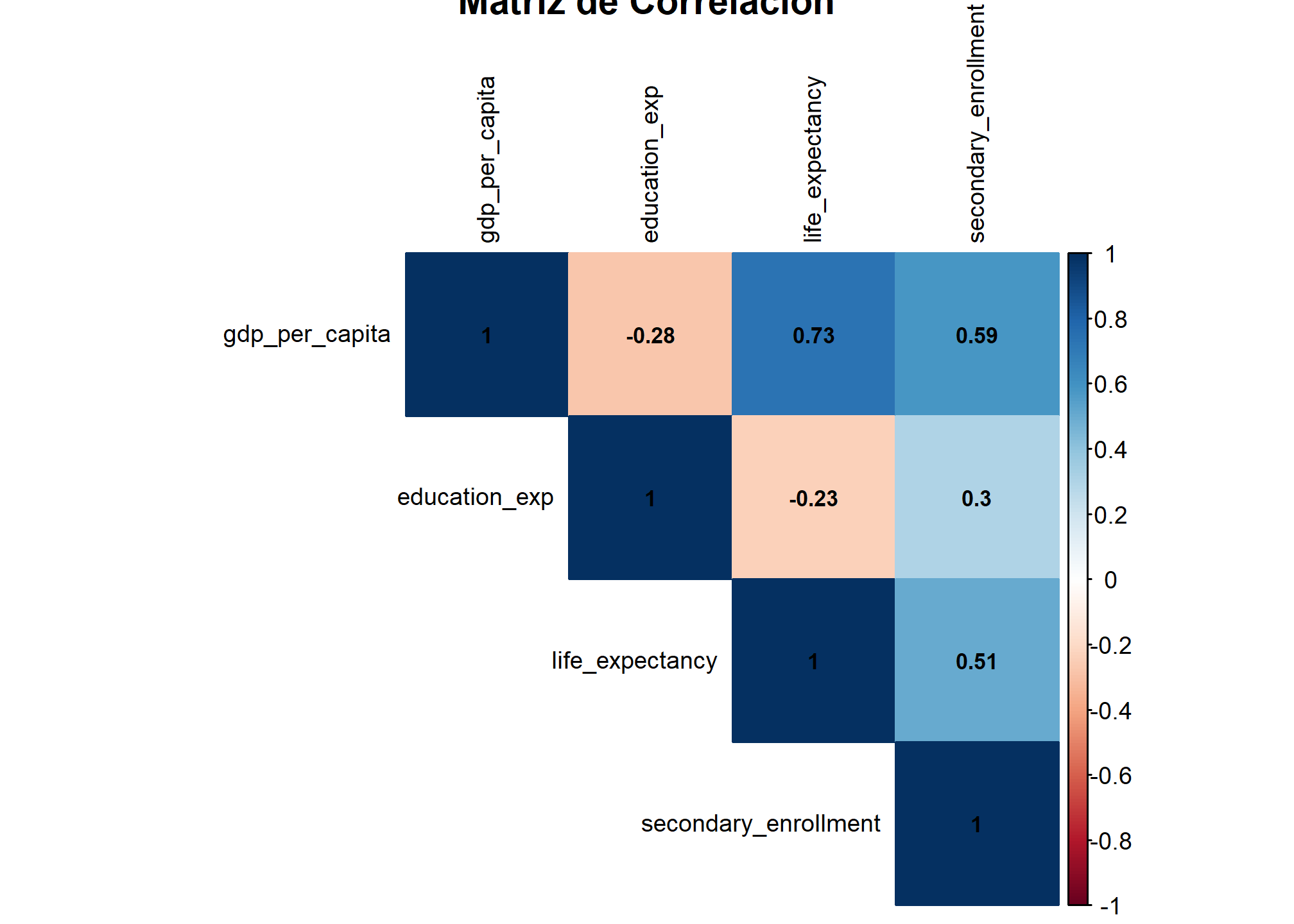
La matriz de correlación nos ayuda a visualizar la relación entre las diferentes variables. Esto es importante porque una alta correlación entre variables podría indicar redundancia y potencialmente afectar la calidad del agrupamiento.
3. Estandarización de las Variables
Antes de proceder al análisis de conglomerados, es fundamental estandarizar las variables. Esto se debe a que las variables tienen diferentes unidades y escalas, lo que podría sesgar el cálculo de las distancias.
# Estandarizar las variables
indicadores_scaled <- indicadores_clean %>%
select(gdp_per_capita, education_exp, life_expectancy, secondary_enrollment) %>%
scale()
# Verificar los datos estandarizados
head(indicadores_scaled)
## gdp_per_capita education_exp life_expectancy secondary_enrollment
## 2 -0.2118599 0.1552978 0.6154511 0.8295064
## 5 0.4976986 -0.5713154 0.8167398 0.4302505
## 6 -0.4313439 0.1224160 -0.5095668 -0.4680960
## 7 -0.5416879 1.7819984 -2.7800194 -0.3353742
## 8 -0.3091451 0.4098854 0.2563248 0.4086305
## 10 4.7011913 -1.8117876 1.4928499 -0.5720380
Hemos estandarizado las variables para que tengan media cero y desviación estándar uno. Esto asegura que cada variable contribuya de igual manera al análisis de distancia y no domine debido a su escala.
4. Matriz de Distancias
El siguiente paso consiste en calcular la matriz de distancias, que será utilizada para formar los conglomerados. Utilizaremos la distancia euclidiana, la cual es adecuada para datos métricos.
# Calcular la matriz de distancias
set.seed(123) # Para reproducibilidad
distancia <- dist(indicadores_scaled, method = "euclidean")
Utilizamos la distancia euclidiana porque nos interesa medir la cercanía entre los países en términos de los indicadores socioeconómicos estandarizados.
5. Análisis de Conglomerados Jerárquico
Procedemos ahora a realizar el análisis de conglomerados jerárquico, utilizando el método de enlace completo (complete linkage). Este método busca maximizar la distancia entre conglomerados, lo cual resulta en grupos compactos.
# Realizar el análisis de conglomerados jerárquico (método de enlace completo)
hc <- hclust(distancia, method = "complete")
# Visualizar el dendrograma
plot(hc, labels = indicadores_clean$country, main = "Dendrograma de Clustering Jerárquico", xlab = "País", sub = "", cex = 0.6)

El dendrograma muestra cómo los países se agrupan de manera jerárquica. La altura de las líneas en el dendrograma indica la distancia a la cual los conglomerados se unen. Podemos observar a qué nivel de corte se forman diferentes conglomerados.
6. Determinación del Número Óptimo de Conglomerados
Para determinar el número óptimo de conglomerados, podemos observar el dendrograma y usar métodos cuantitativos, como el método de la altura del dendrograma (codo o silueta).
# Método del codo para determinar el número óptimo de conglomerados
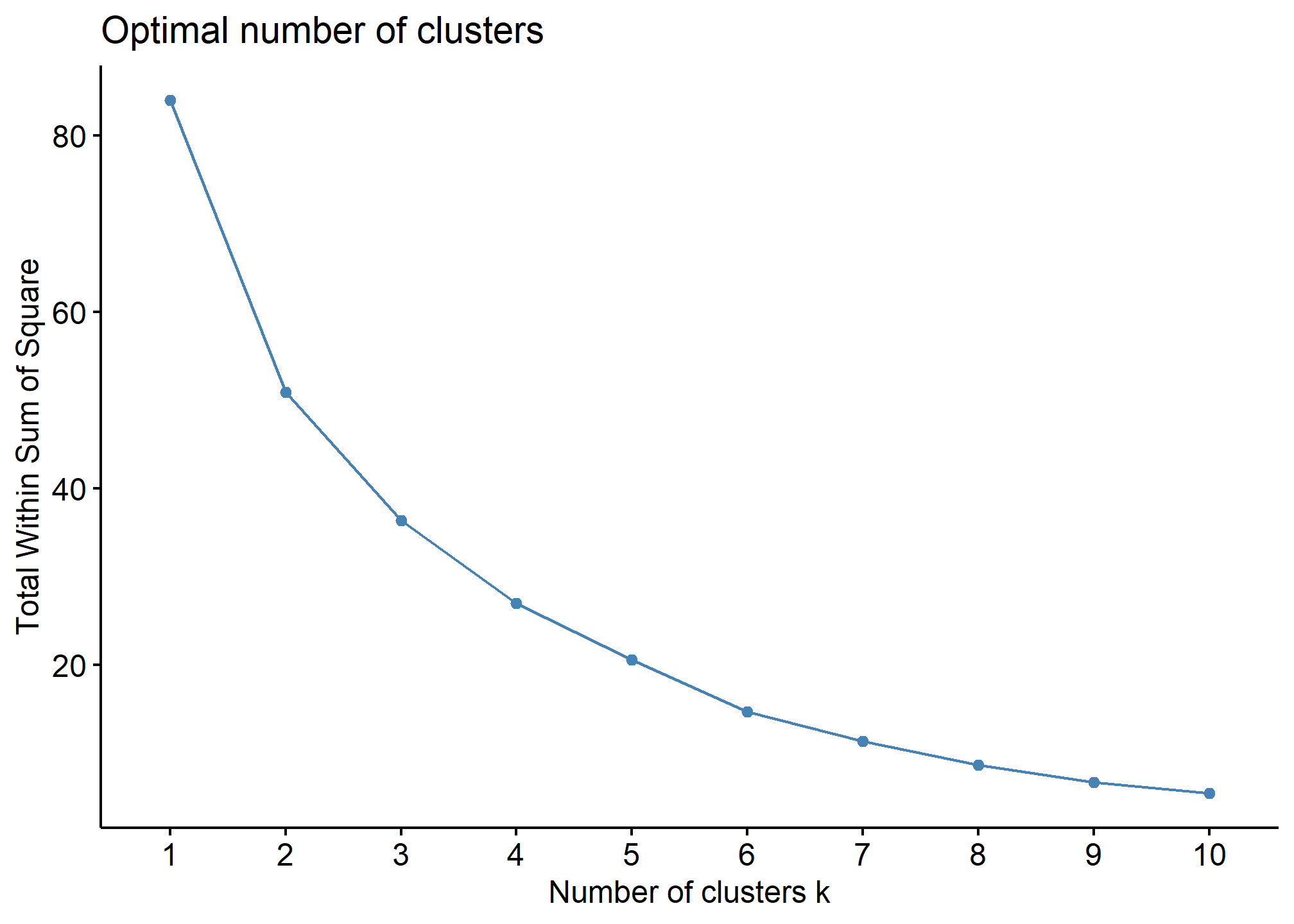
fviz_nbclust(indicadores_scaled, FUN = hcut, method = "wss")
## Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
## ℹ Please use the `linewidth` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
## Warning: The `size` argument of `element_rect()` is deprecated as of ggplot2 3.4.0.
## ℹ Please use the `linewidth` argument instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
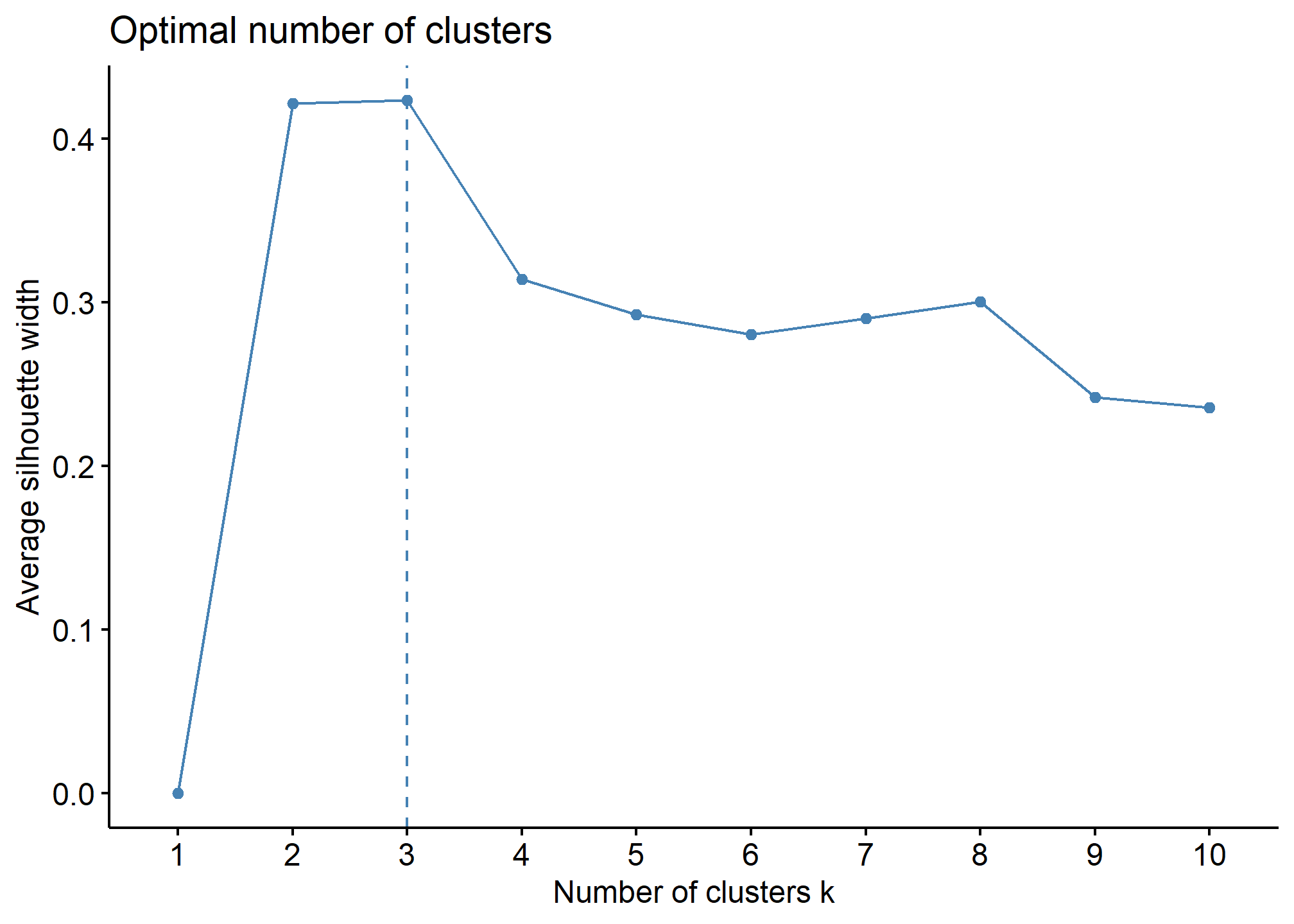
# Índice de silueta para determinar el número óptimo de conglomerados
fviz_nbclust(indicadores_scaled, FUN = hcut, method = "silhouette")
El gráfico del método del codo muestra la suma total de los cuadrados intra-cluster en función del número de conglomerados. La idea es identificar el “punto de codo”, es decir, el número de conglomerados a partir del cual añadir más grupos no genera una gran disminución en la variabilidad intra-cluster. En nuestro caso, parece que el punto de codo se encuentra alrededor de 3 conglomerados, ya que a partir de este valor la reducción de la variabilidad comienza a ser menos pronunciada. Esto sugiere que 3 conglomerados podrían ser una elección adecuada, ya que proporciona una buena separación sin sobreajustar.
El gráfico del índice de silueta nos ayuda a evaluar la cohesión y separación de los conglomerados. Este índice mide qué tan bien se agrupan los puntos dentro de cada conglomerado, con valores más altos indicando una mejor separación entre conglomerados. En nuestro gráfico, el valor más alto del índice de silueta se observa con 3 conglomerados, lo cual confirma la elección sugerida por el método del codo. Un valor alto indica que las observaciones dentro de un conglomerado son similares entre sí, mientras que están bien separadas de los otros conglomerados. En general, el índice de silueta apoya la idea de usar 3 conglomerados como el número óptimo
7. Visualización y Corte del Dendrograma
Con base en el análisis anterior, procedemos a cortar el dendrograma para obtener los conglomerados. Podemos probar con distintas cantidades de conglomerados, a fin de observar cual es la mejor agrupación.
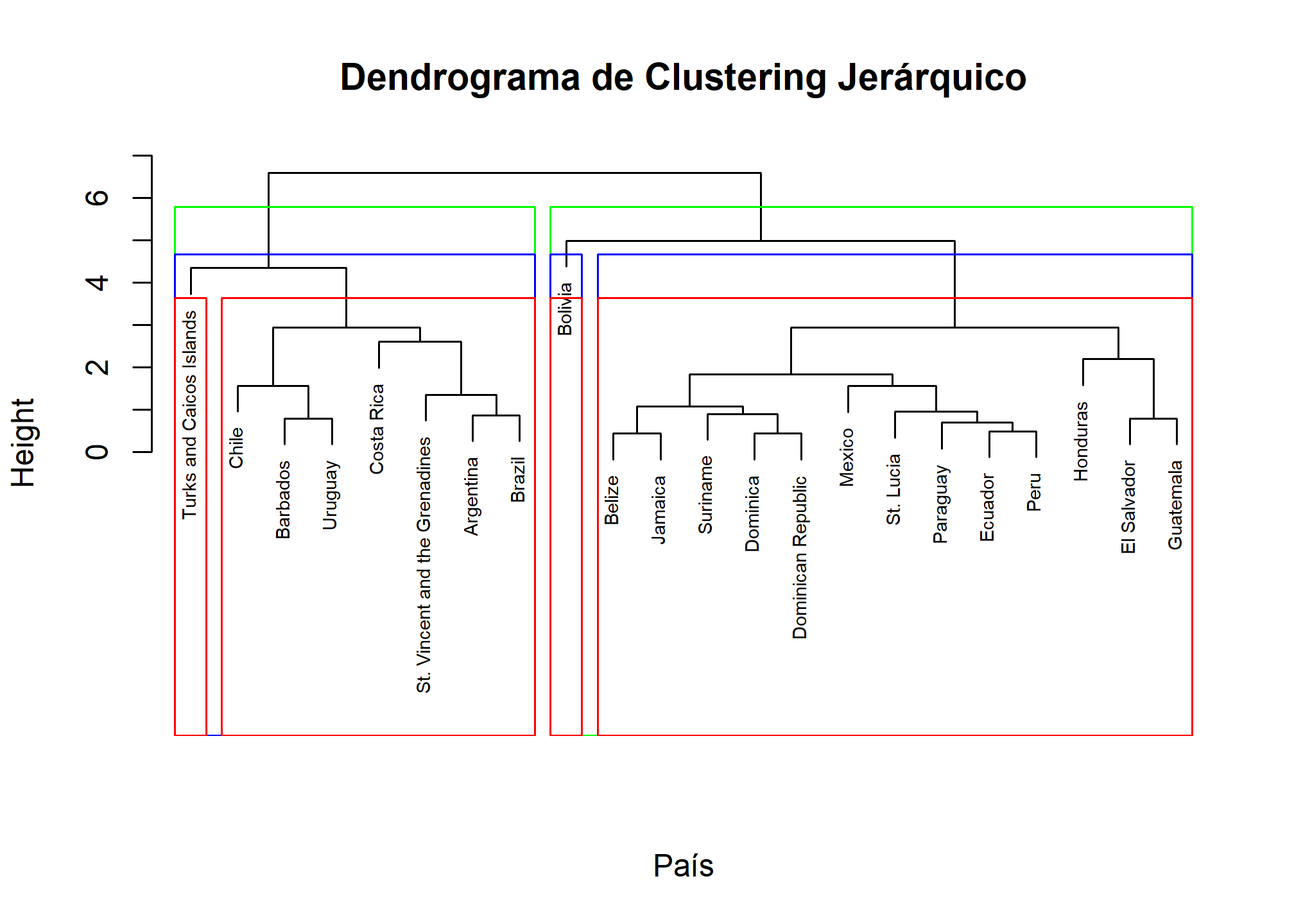
# Cortar el dendrograma para obtener 3 conglomerados
plot(hc, labels = indicadores_clean$country, main = "Dendrograma de Clustering Jerárquico", xlab = "País", sub = "", cex = 0.6)
rect.hclust(hc, k = 2, border = "green")
rect.hclust(hc, k = 3, border = "blue")
rect.hclust(hc, k = 4, border = "red")
grupos <- cutree(hc, k = 3)
# Agregar los conglomerados al dataframe original
indicadores_clean$conglomerado <- grupos
Hemos decidido cortar el dendrograma para obtener 3 conglomerados, representados por los rectángulos azules. Los países dentro de cada conglomerado tienen características socioeconómicas similares.
8. Caracterización de los Conglomerados
A continuación, caracterizamos los conglomerados obtenidos, calculando los promedios de cada variable por conglomerado.
# Caracterización de los conglomerados
caracterizacion <- indicadores_clean %>%
group_by(conglomerado) %>%
summarise(
promedio_gdp_per_capita = mean(gdp_per_capita, na.rm = TRUE),
promedio_education_exp = mean(education_exp, na.rm = TRUE),
promedio_life_expectancy = mean(life_expectancy, na.rm = TRUE),
promedio_secondary_enrollment = mean(secondary_enrollment, na.rm = TRUE),
cantidad_paises = n()
)
# Mostrar la caracterización de los conglomerados con kable y kableExtra
caracterizacion %>%
kbl(caption = "Caracterización de los Conglomerados") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"), full_width = F)
| conglomerado | promedio_gdp_per_capita | promedio_education_exp | promedio_life_expectancy | promedio_secondary_enrollment | cantidad_paises |
|---|---|---|---|---|---|
| 1 | 12277.545 | 5.401196 | 75.22529 | 110.31345 | 14 |
| 2 | 5180.426 | 4.771522 | 71.06983 | 79.47378 | 12 |
| 3 | 82338.798 | 1.455420 | 79.23000 | 84.09091 | 1 |
La tabla de caracterización nos muestra que los tres conglomerados identificados tienen diferencias notables en los indicadores socioeconómicos considerados. A continuación, se amplía la interpretación de estos resultados:
-
Conglomerado 1: Este grupo tiene el PIB per cápita más alto (12,406 USD) y una esperanza de vida alta (76.44 años), lo cual indica un nivel de desarrollo económico relativamente mayor. Sin embargo, el gasto en educación como porcentaje del PIB es moderado (4.99%), y la tasa de matrícula en la educación secundaria es muy elevada (112%). Esto sugiere que estos países, aunque tienen buenos niveles de ingreso y salud, podrían estar invirtiendo en educación de manera menos intensiva en comparación con su PIB, aunque los resultados en términos de matrícula son bastante favorables. Este conglomerado incluye 8 países.
-
Conglomerado 2: En este conglomerado encontramos países con un PIB per cápita moderado (5,694 USD) y una esperanza de vida de 72.36 años, un poco inferior al Conglomerado 1. El gasto en educación es relativamente bajo (4.47%), y la tasa de matrícula en educación secundaria también es la más baja entre los grupos (81.2%). Estos países podrían estar enfrentando limitaciones tanto en términos de ingreso como en inversiones en salud y educación, lo cual se refleja en los indicadores socioeconómicos. Este grupo contiene 13 países, lo cual indica que representa la situación predominante de muchos países en la región.
-
Conglomerado 3: Este conglomerado tiene un PIB per cápita bajo (3,069 USD) y una esperanza de vida significativamente más baja (64.47 años), pero se destaca por un gasto en educación alto (8.44% del PIB). Esto podría indicar que, aunque estos países enfrentan grandes desafíos económicos y de salud, priorizan la inversión en educación como una forma de mejorar sus condiciones socioeconómicas a futuro. La tasa de matrícula en educación secundaria (90%) es también considerablemente alta, lo cual sugiere que la inversión educativa tiene un impacto en el acceso a la educación. Este conglomerado, sin embargo, incluye solamente 1 país, lo cual indica que estas características no son comunes en la región y podrían corresponder a un caso excepcional.
Esta caracterización nos permite entender mejor las diferencias en el desarrollo socioeconómico de los países de América Latina y cómo estas diferencias se agrupan en distintos perfiles. Los resultados también sugieren distintas estrategias en términos de políticas públicas, especialmente en el gasto en educación y sus resultados asociados. El Conglomerado 3, a pesar de tener bajos niveles de PIB y esperanza de vida, muestra un compromiso con la educación que podría ser clave para su desarrollo futuro, mientras que el Conglomerado 1 refleja un mayor desarrollo económico y salud, pero con una inversión en educación que podría ser mejorada en términos relativos.
9. Visualización de Conglomerados
Finalmente, visualizamos los conglomerados en un gráfico de dispersión para entender mejor la formación de los grupos.
# Visualización de los grupos en un gráfico de dispersión
fviz_cluster(list(data = indicadores_scaled, cluster = grupos),
geom = "point", labelsize = 10, main = "Visualización de Conglomerados por País")
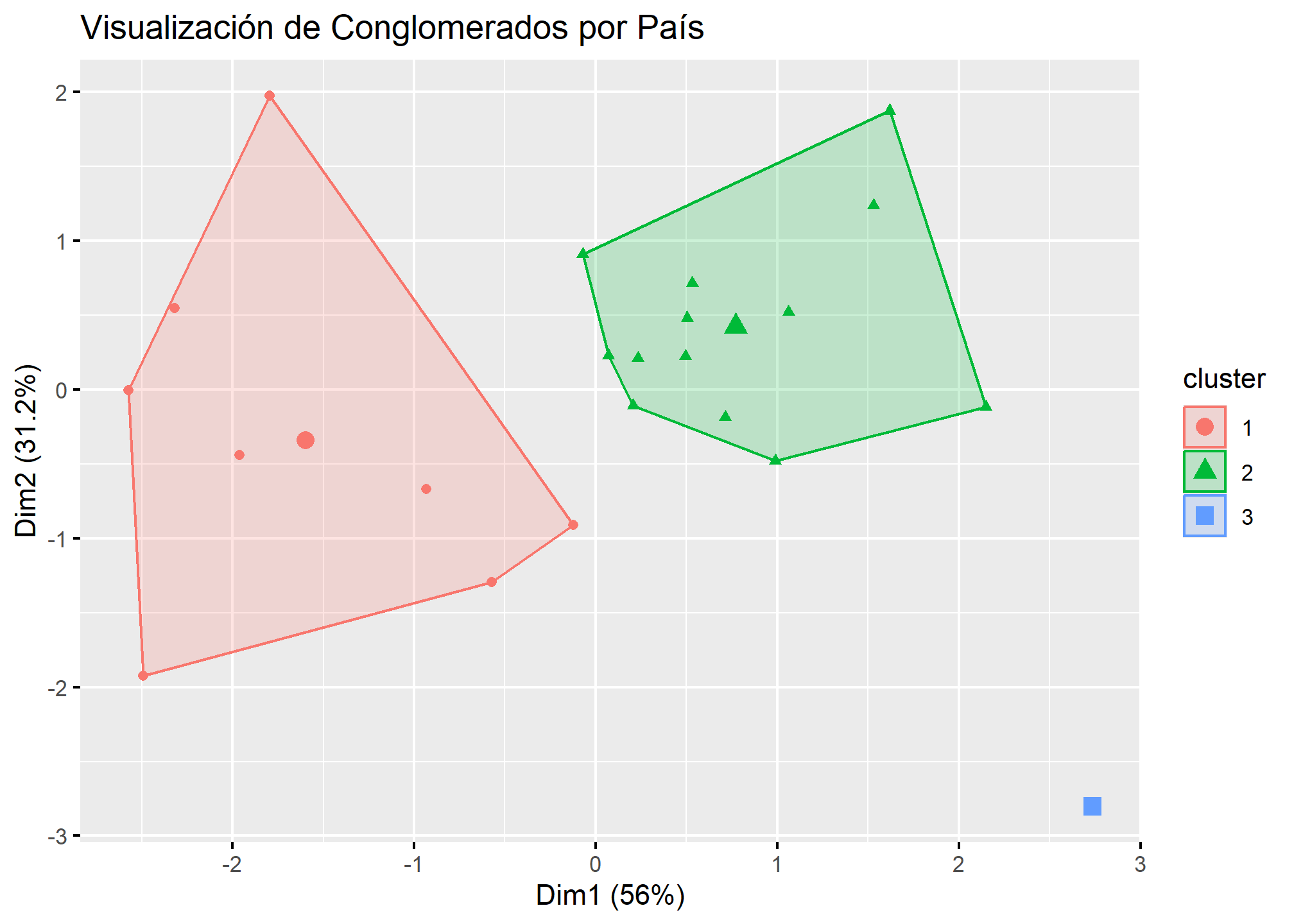
En este gráfico de dispersión, los puntos representan a los países y están coloreados según el conglomerado al cual pertenecen. Podemos ver cómo los conglomerados están separados y si existe alguna superposición.
Con esto, hemos completado un análisis de conglomerados jerárquico sobre datos socioeconómicos de países de América Latina. Esta técnica es útil para identificar patrones ocultos en los datos y agrupar observaciones en base a su similitud.