Análisis de regresión lineal múltiple II
0. Objetivo del práctico
En este práctico aprenderemos a aplicar la regresión lineal múltiple en R, utilizando variables continuas, dicotómicas y categóricas, para entender cómo influencian una variable dependiente. También profundizaremos en el proceso de parcialización para controlar el efecto de las variables independientes y aislar el efecto de cada predictor.
1. Cargar los datos de la encuesta CASEN
Primero, cargamos los datos de la CASEN y seleccionamos las variables que nos interesan: los ingresos del trabajo, los años de escolaridad, la edad, el sexo y el nivel educativo.
if (!require(pacman)) {
install.packages("pacman")
}
## Loading required package: pacman
pacman::p_load(haven, dplyr, texreg, corrplot)
temp <- tempfile() #Creamos un archivo temporal
download.file("https://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/casen/2022/Base%20de%20datos%20Casen%202022%20SPSS.sav.zip",temp) #descargamos los datos
casen <- haven::read_sav(unz(temp, "Base de datos Casen 2022 SPSS.sav")) #cargamos los datos
unlink(temp); remove(temp) #eliminamos el archivo temporal
casen2 <- casen %>%
select(esc, sexo, ytrabajocor, edad, educ)
2. Relación entre los ingresos la escolaridad y la edad
Primero, analizamos cómo los años de escolaridad y la edad afectan los ingresos del trabajo. Empezamos con una exploración de las correlaciones entre estas variables y realizamos regresiones lineales simples y múltiples.
# Seleccionamos las variables del modelo
variables_modelo <- casen2 %>%
select(ytrabajocor, esc, edad)
# Calculamos la matriz de correlación
matriz_correlacion <- cor(variables_modelo, use = "complete.obs")
# Generamos el corrplot
corrplot(matriz_correlacion, method = "color", type = "upper",
tl.col = "black", tl.srt = 45,
addCoef.col = "black", number.cex = 0.7,
cl.cex = 0.8, tl.cex = 0.8, mar = c(0,0,1,0),
title = "Matriz de Correlación")
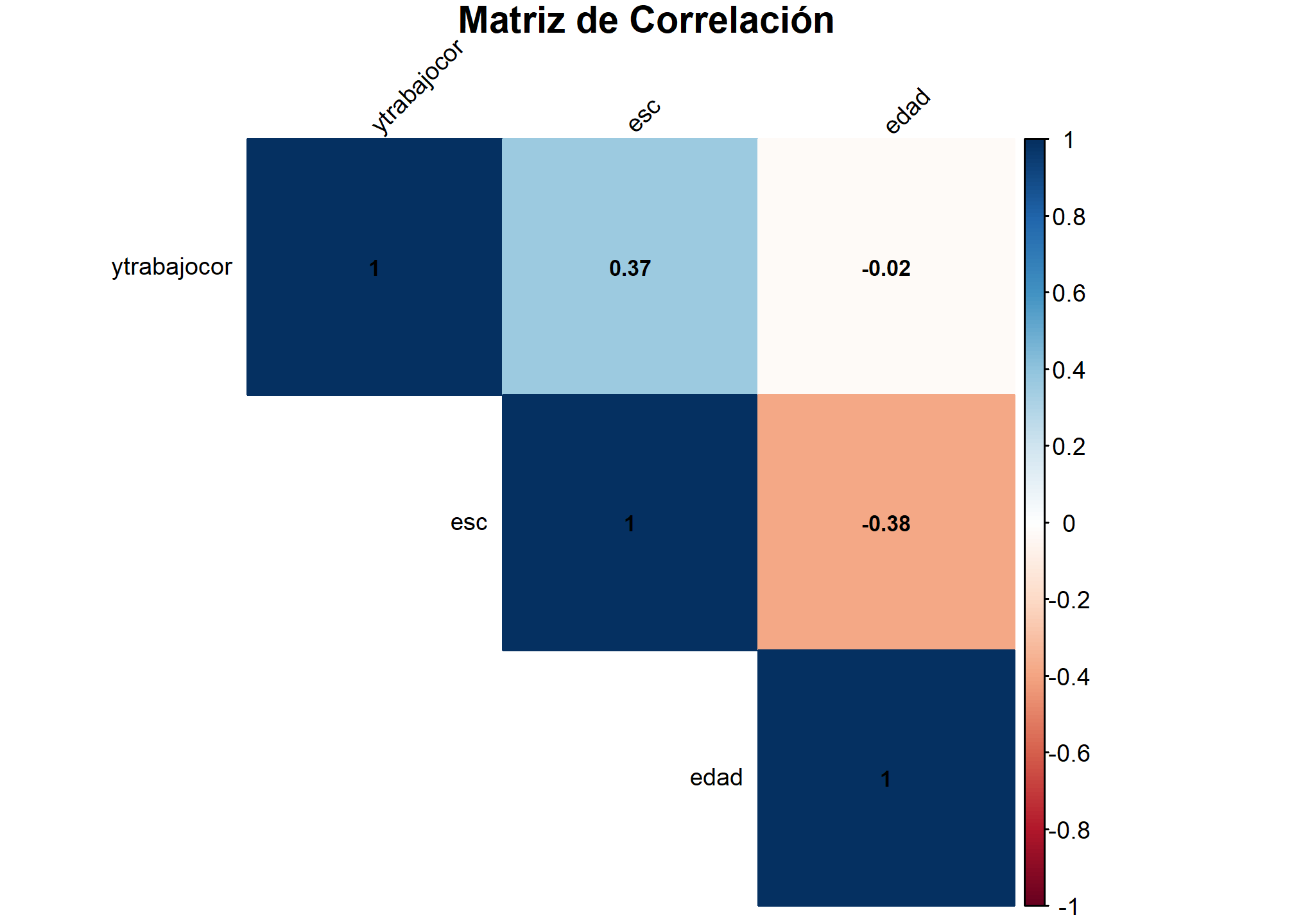
Ahora realizamos regresiones para analizar el efecto de la escolaridad y la edad sobre los ingresos, primero de forma separada y luego conjuntamente a fin de observar al diferencia en la relación de las variables al introducir controles.
modelo1 <- lm(ytrabajocor ~ esc , data = casen2)
modelo2 <- lm(ytrabajocor ~ edad, data = casen2)
modelo3 <- lm(ytrabajocor ~ esc + edad, data = casen2)
htmlreg(list(modelo1,modelo2,modelo3))
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| (Intercept) | -272321.52*** | 729366.06*** | -742740.49*** |
| (8405.83) | (8757.98) | (14303.97) | |
| esc | 77114.51*** | 88022.20*** | |
| (656.62) | (704.29) | ||
| edad | -1403.43*** | 7681.28*** | |
| (189.32) | (189.88) | ||
| R2 | 0.13 | 0.00 | 0.15 |
| Adj. R2 | 0.13 | 0.00 | 0.15 |
| Num. obs. | 88391 | 88976 | 88391 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
#screenreg(list(modelo1,modelo2,modelo3))
Modelo 1 (Escolaridad): El coeficiente para escolaridad es 77,114. Esto significa que por cada año adicional de escolaridad, los ingresos del trabajo aumentan en promedio 77,114 unidades monetarias.
Modelo 2 (Edad): El coeficiente para edad es -1,403. Esto sugiere que, por cada año adicional de edad, los ingresos disminuyen en promedio 1,403 unidades, lo que podría reflejar efectos de antigüedad o envejecimiento en el mercado laboral.
Modelo 3 (Escolaridad y Edad):
Al considerar ambos predictores juntos, el coeficiente de escolaridad aumenta a 88,022, lo que sugiere que parte del impacto de la escolaridad estaba siendo “ocultado” por la edad. El coeficiente de edad cambia a 7,681, lo que indica que, al controlar por la escolaridad, la edad tiene un efecto positivo en los ingresos.
3. Incluir predictores dicotómicos en el modelo
El sexo es una variable dicotómica en este modelo. Las variables dicótomicas deben ser codificadas como 0 y 1 para integrarlas apropiadamente al modelo, y poder interpretar el beta como la diferencia promedio entre los grupos, controlando por las demás variables del modelo. R hace automáticamente esto si la variable introducida es de tipo factor (o le decimos que la trate como tal con la función factor())
modelo1 <- lm(ytrabajocor ~ esc , data = casen2)
modelo2 <- lm(ytrabajocor ~ factor(sexo), data = casen2)
modelo3 <- lm(ytrabajocor ~ esc + factor(sexo), data = casen2)
htmlreg(list(modelo1,modelo2,modelo3))
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| (Intercept) | -272321.52*** | 741995.12*** | -207194.28*** |
| (8405.83) | (3648.82) | (8426.08) | |
| esc | 77114.51*** | 80356.85*** | |
| (656.62) | (652.68) | ||
| factor(sexo)2 | -167442.22*** | -235612.34*** | |
| (5477.45) | (5113.14) | ||
| R2 | 0.13 | 0.01 | 0.16 |
| Adj. R2 | 0.13 | 0.01 | 0.16 |
| Num. obs. | 88391 | 88976 | 88391 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
#screenreg(list(modelo1,modelo2,modelo3))
Modelo 2 (Sexo): El coeficiente para sexo es -167,442. Esto significa que los hombres ganan en promedio 167,442 unidades más que las mujeres, cuando no se controla por ninguna otra variable.
Modelo 3 (Escolaridad y Sexo): Al incluir tanto la escolaridad como el sexo, los hombres ganan 235,612 unidades más que las mujeres en promedio, lo que sugiere que la brecha salarial de género se mantiene incluso después de controlar por los años de escolaridad.
4. Inclusión de variables categóricas politómicas en RLM
Vamos a transformar la variable de nivel educativo en un conjunto de variables dummies para incluirlas en el modelo. Esto nos permitirá comparar distintos niveles educativos entre sí.
casen2 <- casen2 %>%
mutate(educ_simple = case_when(
educ %in% c(0, 1, 2, 3, 4) ~ 1, # Sin educación o Básica
educ %in% c(5, 6) ~ 2, # Media completa o incompleta
educ %in% c(7, 8) ~ 3, # Técnico nivel superior
educ %in% c(9, 10, 11, 12) ~ 4 # Profesional o Posgrado
)) %>%
mutate(
dummy_media_completa = ifelse(educ_simple == 2, 1, 0),
dummy_superior_tecnica = ifelse(educ_simple == 3, 1, 0),
dummy_superior_profesional = ifelse(educ_simple == 4, 1, 0)
) %>%
mutate(educ_simple_factor = factor(educ_simple,
levels = c(1, 2, 3, 4),
labels = c("Menos que Media", "Media Completa",
"Superior Técnica", "Superior Profesional")))
| educ_simple_factor | dummy_media_completa | dummy_superior_tecnica | dummy_superior_profesional |
|---|---|---|---|
| Menos que Media | 0 | 0 | 0 |
| Media Completa | 1 | 0 | 0 |
| Superior Técnica | 0 | 1 | 0 |
| Superior Profesional | 0 | 0 | 1 |
modelo1 <- lm(ytrabajocor ~ edad, data = casen2)
modelo2 <- lm(ytrabajocor ~ factor(educ_simple_factor), data = casen2)
modelo2.2 <- lm(ytrabajocor ~ dummy_media_completa+ dummy_superior_tecnica + dummy_superior_profesional, data = casen2)
modelo3 <- lm(ytrabajocor ~ edad + factor(educ_simple_factor), data = casen2)
htmlreg(list(modelo1,modelo2,modelo2.2,modelo3), custom.coef.names = c("Intercepto", "Edad","Media completa (ref. menos que media)",
"Superior Técnica", "Superior Profesional" ,"Media completa (ref. menos que media)",
"Superior Técnica", "Superior Profesional"))
| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| Intercepto | 729366.06*** | 396916.32*** | 396916.32*** | 123364.01*** |
| (8757.98) | (4767.94) | (4767.94) | (11171.52) | |
| Edad | -1403.43*** | 5178.45*** | ||
| (189.32) | (191.43) | |||
| Media completa (ref. menos que media) | 128948.37*** | 128948.37*** | 185782.88*** | |
| (6428.87) | (6428.87) | (6738.36) | ||
| Superior Técnica | 271608.14*** | 271608.14*** | 344560.44*** | |
| (8629.17) | (8629.17) | (9006.92) | ||
| Superior Profesional | 797327.92*** | 797327.92*** | 868457.15*** | |
| (7042.71) | (7042.71) | (7490.44) | ||
| R2 | 0.00 | 0.14 | 0.14 | 0.15 |
| Adj. R2 | 0.00 | 0.14 | 0.14 | 0.15 |
| Num. obs. | 88976 | 88406 | 88406 | 88406 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||||
Interpretación de los coeficientes (Modelo 4)
-
Intercepto:
- El intercepto de 123,364 indica el ingreso promedio estimado para una persona con menos que educación media y cuya edad es 0. Aunque este valor no tiene un significado práctico directo (ya que la edad 0 no es realista), es necesario para el ajuste del modelo.
-
Edad:
- El coeficiente para la edad es 5,178.45. Esto indica que por cada año adicional de edad, los ingresos aumentan en promedio en 5,178.45 unidades, controlando por el nivel educativo. Es decir, si mantenemos constante el nivel educativo, las personas más viejas tienden a ganar más.
-
Media Completa (referencia: menos que media):
- El coeficiente de 185,782.88 sugiere que las personas que completaron la educación media ganan en promedio 185,782.88 unidades más que aquellas con menos que educación media, manteniendo constante la edad.
-
Superior Técnica:
- El coeficiente de 344,560.44 indica que las personas con educación técnica superior ganan en promedio 344,560.44 unidades más que aquellas con menos que media, ajustando por edad.
-
Superior Profesional:
- El coeficiente de 868,457.15 indica que las personas con educación superior profesional ganan en promedio 868,457.15 unidades más que aquellas con menos que media, manteniendo constante la edad.
Interpretación de R² y R² ajustado
-
R² = 0.15: Esto significa que el 15% de la variabilidad en los ingresos del trabajo está siendo explicada por el modelo, que incluye la edad y el nivel educativo.
-
R² ajustado = 0.15: El valor ajustado penaliza el número de predictores incluidos en el modelo, pero como es igual a R², indica que la inclusión de los predictores educativos y de edad es válida para explicar la variabilidad en los ingresos.
En resumen, el modelo sugiere que tanto la edad como los niveles educativos superiores están asociados con mayores ingresos, y estos efectos son moderadamente explicativos (15%) de la variabilidad en los ingresos laborales.
5. Proceso de parcialización
¿Qué es la parcialización?
Cuando tenemos varias variables independientes relacionadas entre sí, como edad y escolaridad, el efecto de cada una puede estar influenciado por la otra. La parcialización consiste en ajustar una variable predictora eliminando el efecto de las otras.
Crear residuos parciales
Podemos ilustrar el proceso de parcialización al ajustar cada variable por las otras y obtener sus residuos.
casen2p<-casen2 %>%
select(ytrabajocor, edad, esc) %>%
filter(!is.na(ytrabajocor) & !is.na(esc) & !is.na(edad))
mod_esc <- lm(esc ~ edad, data = casen2p)
mod_edad <- lm(edad ~ esc, data = casen2p)
casen2pp<-data.frame(casen2p, mod_esc$residuals, mod_edad$residuals)
head(casen2pp)
## ytrabajocor edad esc mod_esc.residuals mod_edad.residuals
## 1 411242 40 15 2.3994976 0.05827002
## 2 590000 64 5 -5.1232380 9.85793176
## 3 520000 34 12 -1.2198185 -10.20183146
## 4 450000 30 12 -1.6326959 -14.20183146
## 5 160000 68 10 0.2896394 20.95810089
## 6 580000 56 8 -2.9489928 6.11803324
Ahora obtenemos la regresión lineal múltiple y las regresiones lineales pero utilizando las variables parcializadas, es decir, los residuos de la construcción de los modelos anteriores.
htmlreg(list(lm(ytrabajocor ~ mod_esc.residuals , data = casen2pp),
lm(ytrabajocor ~ mod_edad.residuals , data = casen2pp),
lm(ytrabajocor ~ esc + edad , data = casen2p)))
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| (Intercept) | 668123.79*** | 668123.79*** | -742740.49*** |
| (2533.54) | (2726.46) | (14303.97) | |
| mod_esc.residuals | 88022.20*** | ||
| (704.54) | |||
| mod_edad.residuals | 7681.28*** | ||
| (204.41) | |||
| esc | 88022.20*** | ||
| (704.29) | |||
| edad | 7681.28*** | ||
| (189.88) | |||
| R2 | 0.15 | 0.02 | 0.15 |
| Adj. R2 | 0.15 | 0.02 | 0.15 |
| Num. obs. | 88391 | 88391 | 88391 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||