4. Regresión Lineal Simple II
0. Objetivo del práctico
El objetivo de este práctico es profundizar en el análisis de regresión lineal simple, centrándonos en la interpretación de los residuos y la evaluación del ajuste del modelo. Trabajaremos con datos comunales para analizar cómo la brecha salarial de género está influenciada por el promedio de años de escolaridad y exploraremos cómo los residuos nos informan sobre la calidad del modelo ajustado.
pacman::p_load(dplyr, ggplot2, texreg)
datos <- readRDS(url("https://github.com/GabrielSotomayorl/aadi2024/raw/main/content/example/input/data/datos.rds")) %>%
select(comuna,ing_prom_hombre, ing_prom_mujer,prom_esc = promedio_anios_escolaridad25_2017, prop_rural_2020, ) %>%
mutate(brecha = (ing_prom_hombre - ing_prom_mujer)/ing_prom_hombre*100)
Modelo de regresión
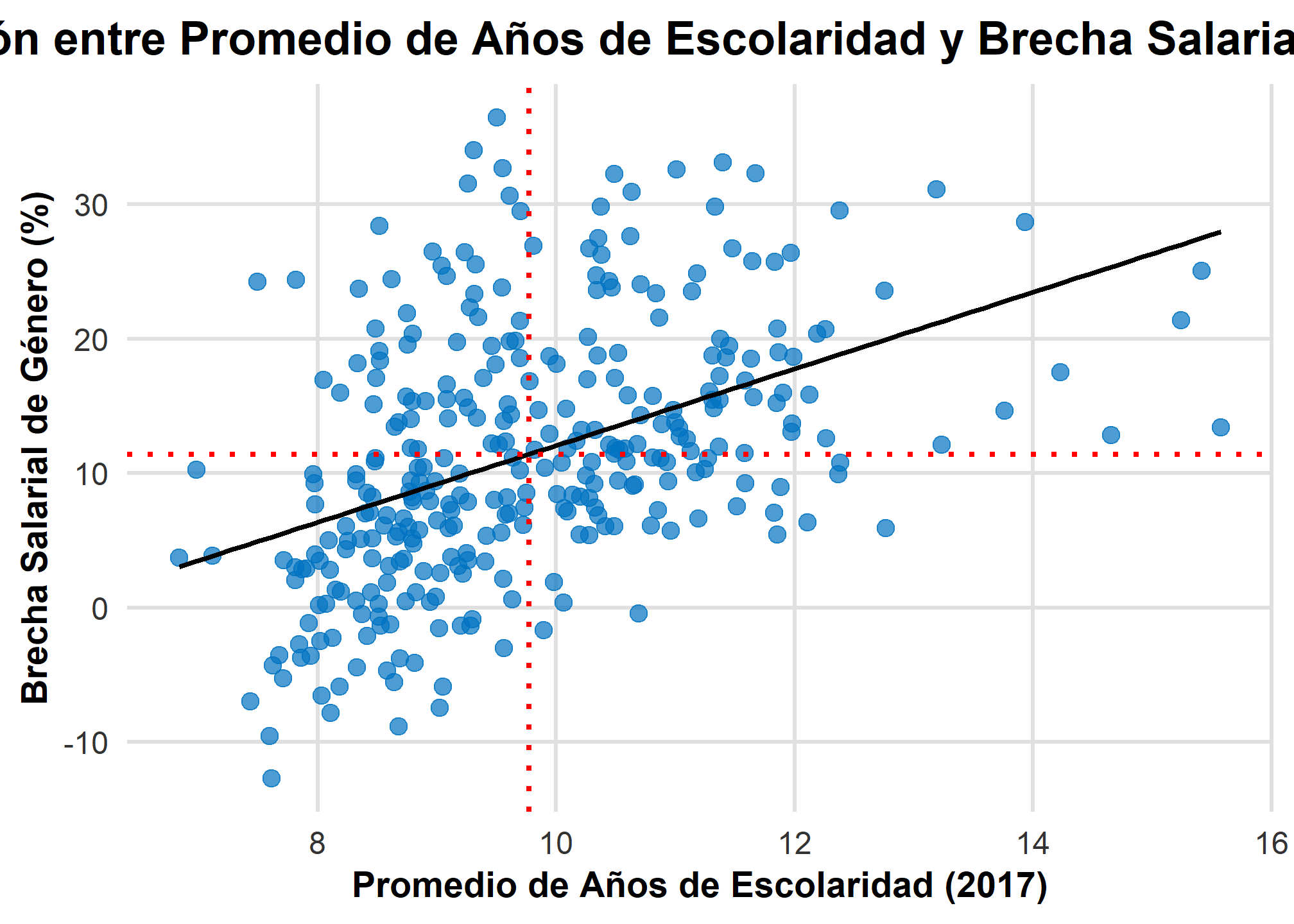
Recordemos nuestro modelo de regresión lineal simple utilizado para analizar la relación entre la amplitud de la brecha salarial de género.
ggplot(datos, aes(x = prom_esc, y = brecha)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7) + # Puntos más grandes y ligeramente transparentes
geom_smooth(method = "lm", color = "black", linetype = "solid", se = FALSE) + # Línea de tendencia en negro
geom_vline(xintercept = mean(datos$prom_esc, na.rm = TRUE), color = "red", linetype = "dotted", size = 1) + # Línea vertical en la media de prom_esc
geom_hline(yintercept = mean(datos$brecha, na.rm = TRUE), color = "red", linetype = "dotted", size = 1) + # Línea horizontal en la media de brecha
labs(
x = "Promedio de Años de Escolaridad (2017)",
y = "Brecha Salarial de Género (%)",
title = "Relación entre Promedio de Años de Escolaridad y Brecha Salarial de Género"
) +
theme_minimal(base_size = 16) + # Tamaño base de letra aumentado
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 18), # Título centrado, en negrita y más grande
axis.title = element_text(face = "bold", size = 14), # Títulos de los ejes en negrita y más grandes
axis.text = element_text(color = "#333333", size = 12), # Texto de los ejes más grande
panel.grid.major = element_line(color = "#e0e0e0"), # Líneas de la cuadrícula mayor en gris claro
panel.grid.minor = element_blank() # Elimina las líneas de la cuadrícula menor
)
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
Utilizamos el paquete texreg para presentar la tabla de regresión. El argumento ‘file’ nos permite guardar la tabla como un archivo, para lo cual debemos poner el nombre del archivo entre comillas, asegurandonos de terminar en “.html”.
modelo <- lm(brecha ~ prom_esc, data = datos)
htmlreg(modelo,
#file = "tabla_regresion.html", #Linea para exportar el archivo
custom.coef.names = c("Intercepto", "Promedio de años de escolaridad"))
| Model 1 | |
|---|---|
| Intercepto | -16.45*** |
| (3.18) | |
| Promedio de años de escolaridad | 2.85*** |
| (0.32) | |
| R2 | 0.20 |
| Adj. R2 | 0.19 |
| Num. obs. | 323 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
¿Cómo interpretamos los coeficientes de regresión?
Residuos
¿Qué son los Residuos?
Los residuos son las diferencias entre los valores observados de la variable dependiente ($Y$) y los valores predichos por el modelo de regresión ($\hat{Y}$). Matemáticamente, se expresan como:
$$ \text{Residuo} = Y_i - \hat{Y}_i $$
Donde:
\(Y_i\)es el valor observado de la variable dependiente.\(\hat{Y}_i\)es el valor predicho por el modelo para la misma observación.
Los residuos son fundamentales para evaluar qué tan bien el modelo se ajusta a los datos. Un modelo que ajusta bien debería tener residuos pequeños y distribuidos de manera aleatoria alrededor de cero.
Cálculo de los Residuos
Utilizaremos la función resid() en R para calcular los residuos del modelo ajustado, y predict() para obtener los valores ajsutados:
# Calcular los residuos del modelo
datos$residuos <- resid(modelo)
#datos$residuos <- modelo$residuals #equivalente
datos$predicciones <- predict(modelo)
#modelo$fitted.values
Gráfico de Residuos vs. Valores Predichos
Un gráfico de residuos vs. valores predichos nos ayuda a identificar patrones en los residuos que podrían sugerir problemas con el modelo, como la no linealidad, la heterocedasticidad (variabilidad no constante), o la presencia de outliers.
# Crear el gráfico de residuos vs valores predichos
ggplot(datos, aes(x = predicciones, y = residuos)) +
geom_point(color = "#0073C2", size = 3, alpha = 0.7) + # Puntos más grandes y ligeramente transparentes
geom_hline(yintercept = 0, color = "red", linetype = "dotted", size = 1) + # Línea horizontal en y=0
labs(
x = "Valores Predichos",
y = "Residuos",
title = "Gráfico de Residuos vs. Valores Predichos"
) +
theme_minimal(base_size = 16) + # Tamaño base de letra aumentado
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 18), # Título centrado, en negrita y más grande
axis.title = element_text(face = "bold", size = 14), # Títulos de los ejes en negrita y más grandes
axis.text = element_text(color = "#333333", size = 12), # Texto de los ejes más grande
panel.grid.major = element_line(color = "#e0e0e0"), # Líneas de la cuadrícula mayor en gris claro
panel.grid.minor = element_blank() # Elimina las líneas de la cuadrícula menor
)
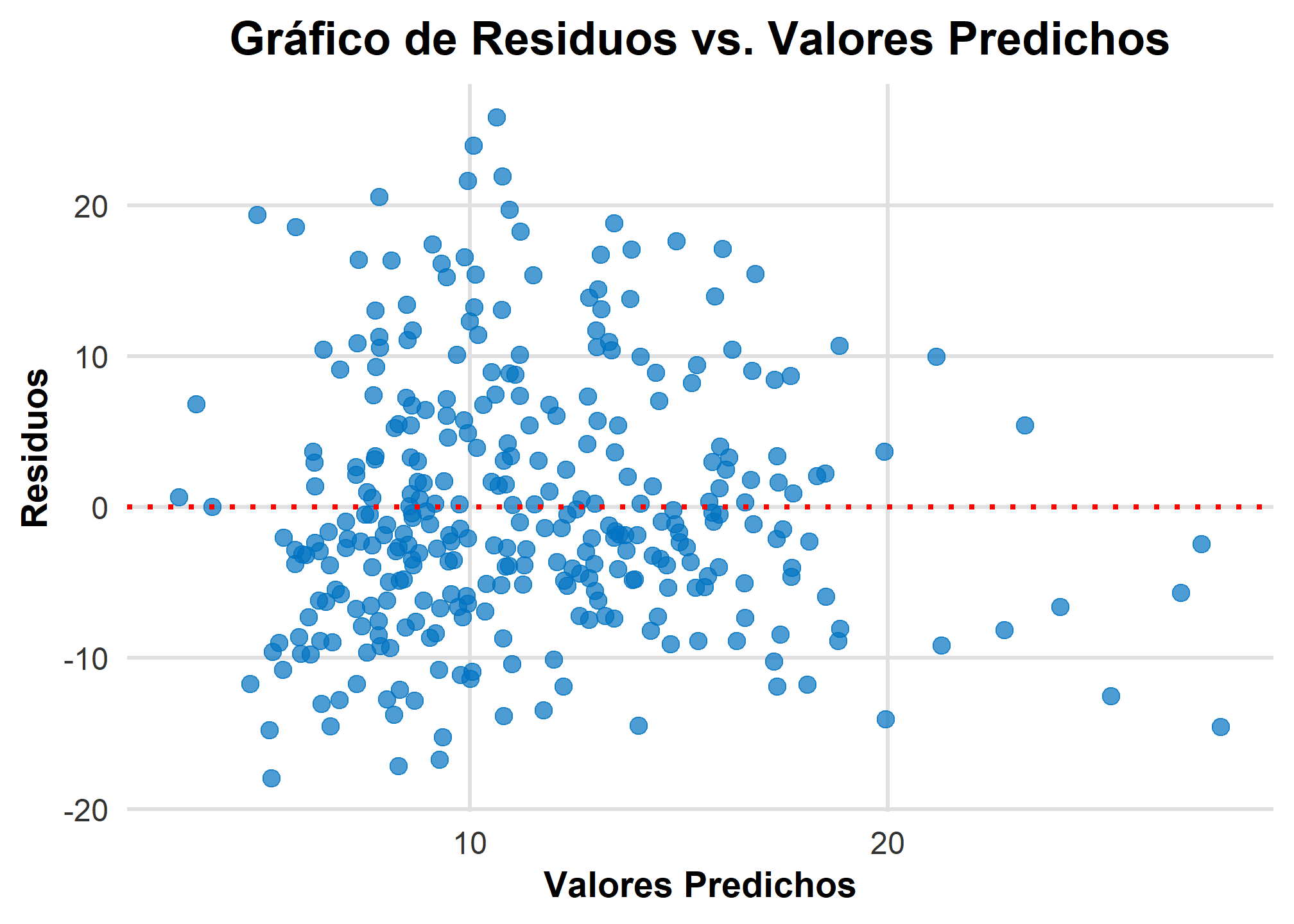
Interpretación del Gráfico de Residuos vs. Valores Predichos
- Distribución aleatoria: Si los residuos están distribuidos de manera aleatoria alrededor de la línea horizontal en cero, el modelo es adecuado.
- Patrones en los residuos: Si se observan patrones (por ejemplo, una curva), esto puede indicar que el modelo no está capturando toda la estructura de los datos, sugiriendo la posibilidad de una relación no lineal.
- Heterocedasticidad: Si la dispersión de los residuos aumenta o disminuye con los valores predichos, esto indica heterocedasticidad, lo que puede afectar la validez de las inferencias.
Histograma de Residuos
Un histograma de residuos es útil para evaluar si los residuos siguen una distribución normal, lo cual es una suposición clave en la regresión lineal simple para ciertas inferencias.
# Crear el histograma de residuos
ggplot(datos, aes(x = residuos)) +
geom_histogram(binwidth = 1, fill = "#0073C2", color = "black", alpha = 0.7) + # Histograma con barras azules
labs(
x = "Residuos",
y = "Frecuencia",
title = "Histograma de Residuos"
) +
theme_minimal(base_size = 16) + # Tamaño base de letra aumentado
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 18), # Título centrado, en negrita y más grande
axis.title = element_text(face = "bold", size = 14), # Títulos de los ejes en negrita y más grandes
axis.text = element_text(color = "#333333", size = 12), # Texto de los ejes más grande
panel.grid.major = element_line(color = "#e0e0e0"), # Líneas de la cuadrícula mayor en gris claro
panel.grid.minor = element_blank() # Elimina las líneas de la cuadrícula menor
)
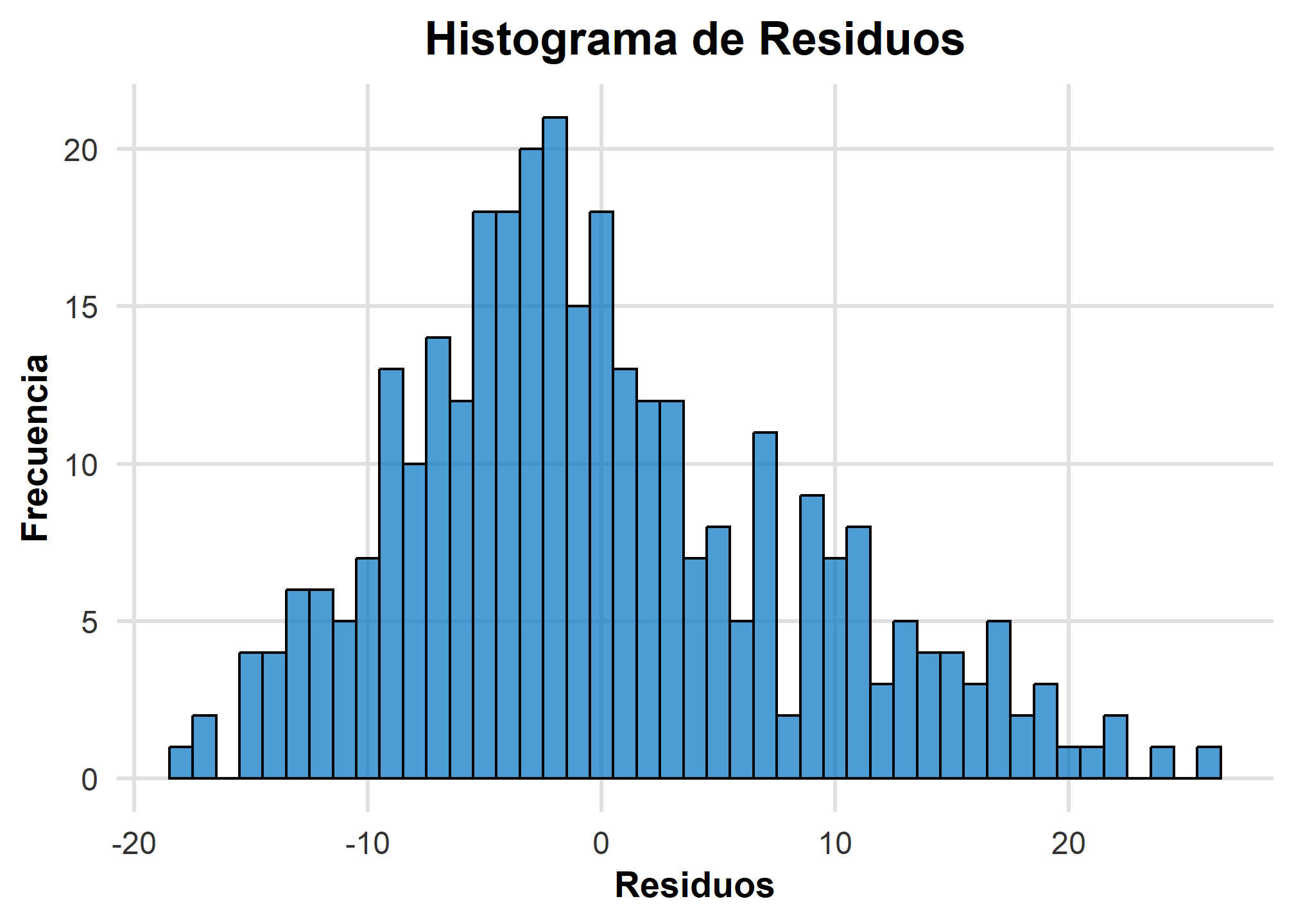
Interpretación del Histograma de Residuos
- Distribución normal: Si los residuos se distribuyen de manera simétrica alrededor de cero y tienen una forma aproximadamente de campana, esto apoya la suposición de normalidad.
- Asimetrías o colas largas: Si el histograma muestra asimetrías pronunciadas o colas largas, esto puede indicar que los residuos no son normalmente distribuidos, lo que podría sugerir la necesidad de revisar el modelo.
Cálculo Manual del \(R^2\) y su Interpretación
El coeficiente de determinación ( R^2 ) es una medida clave en la regresión lineal que indica qué proporción de la variabilidad total en la variable dependiente (( Y )) es explicada por la variable independiente (( X )) en el modelo.
Definición de \(R^2\)
El \(R^2\) se define como:
$$ R^2 = 1 - \frac{\text{Suma de Cuadrados de los Residuos (SSR)}}{\text{Suma Total de Cuadrados (SST)}} $$
Donde:
-
SSR (Suma de Cuadrados de los Residuos): Es la suma de los cuadrados de las diferencias entre los valores observados y los valores predichos. Mide la variabilidad de los residuos o la parte no explicada por el modelo.
$$ \text{SSR} = \sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2 $$
-
SST (Suma Total de Cuadrados): Es la suma de los cuadrados de las diferencias entre los valores observados y la media de los valores observados. Mide la variabilidad total en los datos.
$$ \text{SST} = \sum_{i=1}^{n} (Y_i - \bar{Y})^2 $$
Cálculo Paso a Paso
Paso 1: Calcular la Suma Total de Cuadrados (SST)
Primero, calculamos la Suma Total de Cuadrados (SST), que representa la variabilidad total en los valores observados de ( Y ):
# Calcular la media de Y
mean_y <- mean(datos$brecha, na.rm = TRUE)
# Calcular SST
SST <- sum((datos$brecha - mean_y)^2)
SST
## [1] 28961.14
Paso 2: Calcular la Suma de Cuadrados de los Residuos (SSR)
Luego, calculamos la Suma de Cuadrados de los Residuos (SSR), que mide la variabilidad de los residuos o la parte de \(Y\) no explicada por el modelo:
# Calcular SSR
SSR <- sum((datos$residuos)^2, na.rm = TRUE)
SSR
## [1] 23262.24
Paso 3: Calcular \(R^2\)
Finalmente, utilizamos la relación entre SSR y SST para calcular \(R^2\):
# Calcular R^2
R2_manual <- 1 - (SSR / SST)
R2_manual
## [1] 0.1967772
Interpretación del \(R^2\)
Valor de \(R^2\): El valor calculado de \(R^2\) indica la proporción de la variabilidad total en \(Y\) que es explicada por \(X\) en el modelo. Un \(R^2\) cercano a 1 sugiere que el modelo explica una gran parte de la variabilidad de los datos, mientras que un \(R^2\) cercano a 0 indica que el modelo no captura bien la relación entre las variables.
Ejemplo de interpretación: Si obtienes un \(R^2 = 0.20\), significa que el 20% de la variabilidad en la brecha salarial de género se explica por las diferencias en el promedio de años de escolaridad, según el modelo ajustado. El 80% restante se debe a factores no capturados por el modelo.
Ejercicio: Obtención de un modelo de regresión simple a partir de encuestas.
En este ejercicio, vamos a explorar cómo varía el nivel de acuerdo con el matrimonio igualitario según la edad de las personas encuestadas, utilizando los datos de la Encuesta CEP 82 (Oct-Nov 2018). El objetivo es aplicar una regresión lineal simple para analizar la relación entre estas dos variables: el nivel de acuerdo con el matrimonio igualitario y la edad de los encuestados.
Paso 1: Carga de datos
Primero, cargamos los datos de la encuesta desde una fuente en línea y limpiamos los nombres de las variables para facilitar su uso en R.
# Cargar el paquete haven
pacman::p_load(haven,janitor,kableExtra)
# URL del archivo .sav
url <- "https://github.com/GabrielSotomayorl/aadi2024/raw/main/public/data/Encuesta%20CEP%2082%20Oct-Nov%202018%20v1.sav"
# Cargar los datos directamente desde la URL
datos_cep <- read_sav(url) %>%
janitor::clean_names()
Paso 2: Exploración de la variable de interés
Vamos a generar una tabla de frecuencias que nos muestre cómo se distribuyen las respuestas sobre el nivel de acuerdo con el matrimonio igualitario (variable rel_47). Ojo con los casos perdidos.
# Generar tabla de frecuencias
frecuencias <- datos_cep %>%
group_by(rel_47,as_factor(rel_47)) %>%
summarise(Frecuencia = n()) %>%
ungroup() %>%
mutate(Porcentaje = round((Frecuencia / sum(Frecuencia)) * 100, 2))
## `summarise()` has grouped output by 'rel_47'. You can override using the
## `.groups` argument.
# Mostrar la tabla con kable y kableExtra
frecuencias %>%
kable("html", caption = "Tabla de Frecuencias de acuerdo con el matrimonio entre personas del mismo sexo") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))
| rel_47 | as_factor(rel_47) | Frecuencia | Porcentaje |
|---|---|---|---|
| 1 | Muy de acuerdo | 204 | 14.55 |
| 2 | De acuerdo | 338 | 24.11 |
| 3 | Ni de acuerdo ni en desacuerdo | 240 | 17.12 |
| 4 | En desacuerdo | 290 | 20.68 |
| 5 | Muy en desacuerdo | 290 | 20.68 |
| 8 | No sabe | 29 | 2.07 |
| 9 | No contesta | 11 | 0.78 |
Ahora, vamos a calcular algunas estadísticas descriptivas de la edad de los encuestados (ds_p2_exacta). Estas estadísticas nos ayudarán a entender la distribución de la edad en la muestra.
descriptivas <- datos_cep %>%
summarise(
Minimo = min(ds_p2_exacta, na.rm = TRUE),
Q1 = quantile(ds_p2_exacta, 0.25, na.rm = TRUE),
Media = mean(ds_p2_exacta, na.rm = TRUE),
Mediana = median(ds_p2_exacta, na.rm = TRUE),
Q3 = quantile(ds_p2_exacta, 0.75, na.rm = TRUE),
Maximo = max(ds_p2_exacta, na.rm = TRUE),
DesviacionEstandar = sd(ds_p2_exacta, na.rm = TRUE)
)
# Mostrar la tabla con kable y kableExtra
descriptivas %>%
kable("html", caption = "Estadísticas Descriptivas de edad") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))
| Minimo | Q1 | Media | Mediana | Q3 | Maximo | DesviacionEstandar |
|---|---|---|---|---|---|---|
| 18 | 34 | 48.59629 | 48 | 61 | 93 | 17.34183 |
Paso 4: Asignación de valores para casos perdidos
Instrucción: Completa el siguiente código para asignar NA a los valores 8 y 9 de la variable rel_47. Esta limpieza es crucial antes de proceder con el análisis.
datos_cep <- datos_cep %>%
mutate(rel_47 = ifelse())
Paso 5: Modelo de regresión lineal simple
Vamos a crear un modelo de regresión lineal simple donde intentaremos predecir el nivel de acuerdo con el matrimonio igualitario (rel_47) a partir de la edad (ds_p2_exacta).
# Ajustar un modelo de regresión lineal simple
modelocep <- lm()
# Mostrar un resumen del modelo
summary(modelocep)
screenreg()
Interprete los coeficientes del modelo.
Paso 6: Visualización del modelo
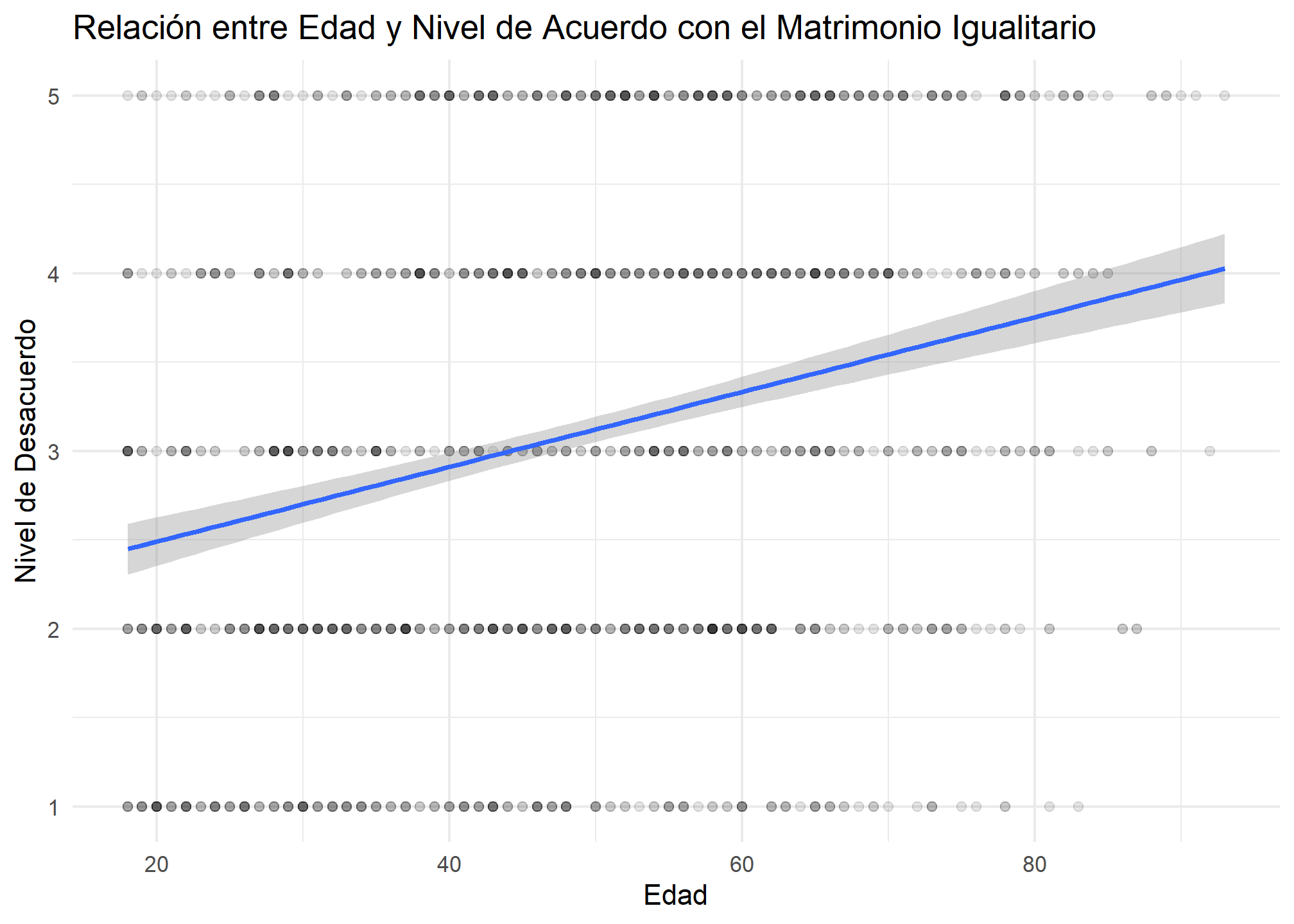
Finalmente, vamos a visualizar la relación entre la edad y el nivel de acuerdo con el matrimonio igualitario mediante un gráfico de dispersión, añadiendo la línea de regresión. Dado que estamos trabajando con una gran cantidad de casos, y con variables con pocos niveles, es importante que asignemos un valor de transparencia bajo a los puntos para que el gráfico de dispersión sea informativo.
# Crear un gráfico de dispersión con la línea de regresión
ggplot(datos_cep, aes(x = , y = )) +
geom_point(alpha = 0.1) +
geom_smooth() +
labs(
title = "Relación entre Edad y Nivel de Acuerdo con el Matrimonio Igualitario",
x = "Edad",
y = "Nivel de Desacuerdo"
) +
theme_minimal()
Versión resuelta del código
Paso 4: Asignación de valores para casos perdidos
Instrucción: Completa el sigueinte código para asignar NA a los valores 8 y 9 de la variable rel_47. Esta limpieza es crucial antes de proceder con el análisis.
datos_cep <- datos_cep %>%
mutate(rel_47 = ifelse(rel_47 %in% 8:9, NA, rel_47))
Paso 5: Modelo de regresión lineal simple
Vamos a crear un modelo de regresión lineal simple donde intentaremos predecir el nivel de acuerdo con el matrimonio igualitario (rel_47) a partir de la edad (ds_p2_exacta).
# Ajustar un modelo de regresión lineal simple
modelocep <- lm(rel_47~ ds_p2_exacta, data = datos_cep)
# Mostrar un resumen del modelo
#summary(modelocep)
#screenreg(modelocep, custom.coef.names = c("Interpecto", "Edad"))
htmlreg(modelocep,
custom.coef.names = c("Interpecto", "Edad"))
| Model 1 | |
|---|---|
| Interpecto | 2.07*** |
| (0.11) | |
| Edad | 0.02*** |
| (0.00) | |
| R2 | 0.07 |
| Adj. R2 | 0.07 |
| Num. obs. | 1362 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Intercepto: El valor del intercepto es 2.07. Este valor, en teoría, representaría el nivel de desacuerdo predicho para una persona cuya edad es 0 años. Sin embargo, dado que en la práctica no existen personas con edad cercana a 0 en el contexto del estudio, el intercepto carece de una interpretación sustantiva real. Es más útil como un parámetro técnico necesario para el ajuste del modelo.
Coeficiente de Edad: El coeficiente para la edad es 0.02. Esto indica que, en promedio, por cada año adicional de edad, el nivel de desacuerdo con el matrimonio igualitario aumenta en 0.02 puntos. Es decir, las personas mayores tienden a estar ligeramente más en desacuerdo con el matrimonio igualitario en comparación con las personas más jóvenes. Esta relación es pequeña, pero positiva, sugiriendo que, a medida que las personas envejecen, hay una tendencia a moverse hacia un mayor desacuerdo.
$R^2$: El valor de es 0.07, lo que significa que la edad explica el 7% de la variabilidad en el nivel de desacuerdo con el matrimonio igualitario. Aunque esto indica que la edad tiene algún efecto, la mayor parte de las diferencias en las actitudes hacia el matrimonio igualitario no se explican por la edad, lo que sugiere que otros factores son más importantes.
Paso 6: Visualización del modelo
Finalmente, vamos a visualizar la relación entre la edad y el nivel de acuerdo con el matrimonio igualitario mediante un gráfico de dispersión, añadiendo la línea de regresión. Dado que estamos trabajando con una gran cantidad de casos, y con variables con pocos niveles, es importante que asignemos un valor de transparencia bajo a los puntos para que el gráfico de dispersión sea informativo. Debemos especificar ‘method = “lm”’ en geom_smooth, para que la linea graficada corresponda a una recta de regresión lineal.
# Crear un gráfico de dispersión con la línea de regresión
ggplot(datos_cep, aes(x = ds_p2_exacta, y = rel_47)) +
geom_point(alpha = 0.1) +
geom_smooth(method = "lm") +
labs(
title = "Relación entre Edad y Nivel de Acuerdo con el Matrimonio Igualitario",
x = "Edad",
y = "Nivel de Desacuerdo"
) +
theme_minimal()
## `geom_smooth()` using formula = 'y ~ x'